Pref
找工作那些事,八股文、面试。
OS
计网
Open System Interconnection Model
应用层(application layer)OSI Layer 7
表示层(presentation layer)OSI Layer 6
会话层(session layer)OSI Layer 5
传输层(transport layer)OSI Layer 4
网络层(network layer)OSI Layer 3
数据链路层(data link layer)OSI Layer 2
物理层(physical layer)OSI Layer 1
物联网叔会使用
根据信息在传输线上的传送方向,分为以下三种通信方式:
单工通信:单向传输
半双工通信:双向交替传输
全双工通信:双向同时传输
半双工:对讲机
全双工:打电话
CSMA/CD: 载波监听多点接入 / 碰撞检测(Detect)
CSMA/CA: 载波监听多点接入 / 碰撞避免(Avoid)
反正我只知道CSMA/CD用于有线局域网(LAN),CSMA/CA用于无线局域网(WIFI)
子网作用是什么?
好比送情书,寝室的位置比如哪栋就是网络号,
哪层就是子网号,寝室号就是主机号
RIP(Routing Informaiton Protocols)路由信息协议
OSPF(Open Shortest Path First)开放式最短路径优先协议
BGP(Border Gateway Protocol)边界网关协议
AS(autonomous system)自治系统
UDP 和 TCP 的特点
用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
TCP 首部格式
ACK: Acknowledgement(确认)
SYN: Synchronization(同步)
FIN: Finish(终止)
看了网上一个比喻觉得很对:
TCP三次握手就像和朋友打电话:
客户端: 喂, 你听到到我说话吗
服务器: 可以,你听到得到我吗
客户端: 我也听得到,开传!
如果没有TCP三次握手,服务器收到请求就打开链接,等待客户端的传输。但由于此时实际上没有传输的必要,服务器凭空的一直等待会导致资源的浪费。有了TCP后,如果客户端收到第二次服务器的确认建立连接报文后就不会给予回应,服务器也就不会打开两个通道导致资源浪费了。
三次握手的目的是连接服务器指定端口,建立 TCP 连接,并同步连接双方的序列号和确认号,交换 TCP 窗口大小信息。在 socket 编程中,客户端执行 connect() 时。将触发三次握手。
tcp.jpg
TCP 的四次挥手
客户端A:分手!发送FIN(不发微信了)
服务器B:啊?真的要分手吗?(发微信问问)
服务器B:(A没来信)算了那就分吧!发送FIN
客户端A:收到B的来信,发送“好的”,然后进入等待状态,确认再也没信了就拉黑
服务器B:收到A的来信,直接拉黑A
1.客户端:我想中断。
2.服务器:好吧,等我收完刚刚的数据。
3.服务器:我收完了,再见!
4.客户端:再见!
客户端:我话说完;
服务器:好的,知道了;(双向→单向通信)
服务器:我话说完了;
客户端:好的,知道了。
最终结果→断开
tcp标志位,有6种标示:
SYN(synchronous建立联机)
ACK(acknowledgement 确认)
PSH(push传送)
FIN(finish结束)
RST(reset重置)
URG(urgent紧急)
Sequence number(顺序号码)
Acknowledge number(确认号码)
TCP 滑动窗口
知乎上看到的一段,很清晰
看这个场景, 老师说一段话, 学生来记.
老师说”从前有个人, 她叫马冬梅. 她喜欢他, 而他却喜欢她.”
学生写道”从前有..”.
“老师你说的太快我跟不上”
于是他们换了一种模式.
老师说”从”
学生写”从”. 学生说”嗯”
老师说”前”
学生写”前”.学生说”嗯”
老师说”今天我还想早点下班呢…”
于是他们换了一种模式.
老师说”从前有个人”
学生写”从前有个人”. 学生说”嗯”
老师说”她叫马冬梅”.
学生写”她叫马…梅”.学生说”马什么梅?”
老师说”她叫马冬梅”.
学生写”她叫马冬…”. 学生说”马冬什么?”
老师”…..”
学生说”有的时候状态好我能把5个字都记下来, 有的时候状态不好就记不下来.我状态不好的时候你能不能慢一点. “于是他们换了一种模式
老师说”从前有个人”
学生写”从前有个人”. 学生说”嗯, 再来5个”
老师说”她叫马冬梅”
学生写”她叫马..梅”. 学生说”啥?重来, 来2个”
老师说”她叫”
学生写”她叫”. 学生说”嗯,再来3个”
老师说”马冬梅”.
学生写”马冬梅”. 学生说”嗯, 给我来10个”
老师说”她喜欢他,而他却喜欢她”学生写…
所以呢
第一种模式简单粗暴, 发的只管发, 收的更不上.
第二种模式稳定却低效, 每发一个, 必须等到确认才再次发送, 等待时间很多.
第三种模式提高了效率, 分组进行发送, 但是分组的大小该怎么决定呢?
第四中模式才是起到了流控的作用, 接收方认为状态好的时候, 让发送方每次多发一点. 接收方认为状态不好的时候(阻塞), 让发送方每次少发送一点.
TCP的流量控制是接收方控制发送方的发送速度,拥塞控制是去全局的网络状态来控制发送方的发送速度,当需要确定发送方的发送速度时,取流量控制和拥塞控制要求发送速率的最小值
电子邮件协议
SMTP(Simple Mail Transfer Protocol) 简单邮件传输协议
IMAP(Internet Message Access Protocol)交互邮件访问协议
MIME(Multipurpose Internet Mail Extensions) 多用途互联网邮件扩展类型
常用端口
| 应用 | 应用层协议 | 端口号 | 传输层协议 | 备注 |
|---|---|---|---|---|
| 域名解析 | DNS | 53 | UDP/TCP | 长度超过 512 字节时使用 TCP |
| 动态主机配置协议 | DHCP | 67/68 | UDP | |
| 简单网络管理协议 | SNMP | 161/162 | UDP | |
| 文件传送协议 | FTP | 20/21 | TCP | 控制连接 21,数据连接 20 |
| 远程终端协议 | TELNET | 23 | TCP | |
| 超文本传送协议 | HTTP | 80 | TCP | HTTPS 443 端口 |
| 简单邮件传送协议 | SMTP | 25 | TCP | |
| 邮件读取协议 | POP3 | 110 | TCP | |
| 网际报文存取协议 | IMAP | 143 | TCP | |
| 简单文件传输协议 | TFTP | 69 | UDP |
Web 页面请求过程
打开电脑,连接WIFI(或者插上网线)
“1. DHCP 配置主机信息” —— 获得连接网络的能力
打开浏览器输入网址:https://leetcode-cn.com/
“2. ARP 解析 MAC 地址” —— 找到路由器的MAC地址
“3. DNS 解析域名” —— 通过路由表找到DNS服务器,并解析域名对应的IP
“4. HTTP 请求页面” —— 通过IP地址访问到HTTP服务器,浏览器得到HTTP服务器的响应后进行解析和渲染,显示页面。
DHCP 配置主机信息” —— 获得连接网络的能力(具体包括获取自己各种信息及DNS的IP地址、默认网关的IP地址)
ARP 解析 MAC 地址” —— 找到默认网关的MAC地址,方便离开局域网
DNS 解析域名” —— 通过路由表找到DNS服务器,DNS查询报文经默认网关到达DNS服务器,由DNS服务器解析域名对应的IP
HTTP 请求页面” —— 通过IP地址访问到HTTP服务器,自己与服务器三次握手建立连接,浏览器得到HTTP服务器的响应后进行解析和渲染,显示页面。
进程是资源分配的基本单位。
进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,都是指对 PCB 的操作。
线程是独立调度的基本单位。
一个进程中可以有多个线程,它们共享进程资源。
QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。
区别
Ⅰ 拥有资源
进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
Ⅱ 调度
线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
Ⅲ 系统开销
由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
Ⅳ 通信方面
线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助 IPC。
IPC(Inter-Process Communication)进程间通信,提供了各种进程间通信的方法。在Linux C编程中有几种方法
(1) 半双工Unix管道
(2) FIFOs(命名管道)
(3) 消息队列
(4) 信号量
(5) 共享内存
(6) 网络Socket
进程是一辆辆的火车;而线程是火车上的各节车厢
进程状态的切换
就绪状态(ready):等待被调度
运行状态(running)
阻塞状态(waiting):等待资源

应该注意以下内容:
只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
进程调度算法
不同环境的调度算法目标不同,因此需要针对不同环境来讨论调度算法。
- 批处理系统
批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
1.1 先来先服务 first-come first-serverd(FCFS)
非抢占式的调度算法,按照请求的顺序进行调度。
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
1.2 短作业优先 shortest job first(SJF)
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
1.3 最短剩余时间优先 shortest remaining time next(SRTN)
最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
- 交互式系统
交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
2.1 时间片轮转
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:
因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
而如果时间片过长,那么实时性就不能得到保证。
2.2 优先级调度
为每个进程分配一个优先级,按优先级进行调度。
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
2.3 多级反馈队列
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,..。进程在第一个队列没执行完,就会被移到下一个队列。这种方式下,之前的进程只需要交换 7 次。
每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
- 实时系统
实时系统要求一个请求在一个确定时间内得到响应。
分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
套接字(socket)
TCP用主机的IP地址加上主机上的端口号作为TCP连接的端点,这种端点就叫做套接字(socket)或插口。
套接字用(IP地址:端口号)表示,区分不同应用程序进程间的网络通信和连接,主要有3个参数:通信的目的IP地址、使用的传输层协议(TCP或UDP)和使用的端口号。
- 并发
并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
操作系统通过引入进程和线程,使得程序能够并发运行。
- 共享
共享是指系统中的资源可以被多个并发进程共同使用。
有两种共享方式:互斥共享和同时共享。
互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
- 虚拟
虚拟技术把一个物理实体转换为多个逻辑实体。
主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
- 异步
异步指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
基本特征:
(1)并发:交替执行
(2)共享:资源被多个并发进程共同使用,分互斥共享和同事共享
(3)虚拟:物理转换为多个逻辑实体,分时(时间)分复用技术和空(空间)分复用技术
(4)异步:进程不是一次性执行完毕,而是走走停停
并发和共享是操作系统两个最基本的特征,这两者之间又是互为存在条件的。
并发(Concurrence)
共享(Sharing)
虚拟(Virtual)
异步性(Asynchronism)
一般来说,同步中断又称为异常(exception),异步中断称为中断(interrupt)。
同步中断是在指令执行时由CPU主动产生的,受到CPU控制,其执行点是可控的。
异步中断是CPU被动接收到的,由外设发出的电信号引起,其发生时间不可预测。
禁止抢占(no preemption):系统资源不能被强制从一个进程中退出。
持有和等待(hold and wait):一个进程可以在等待时持有系统资源。
互斥(mutual exclusion):资源只能同时分配给一个进程,无法多个进程共享。
循环等待(circular waiting):一系列进程互相持有其他进程所需要的资源。
死锁只有在四个条件同时满足时发生,预防死锁必须至少破坏其中一项。
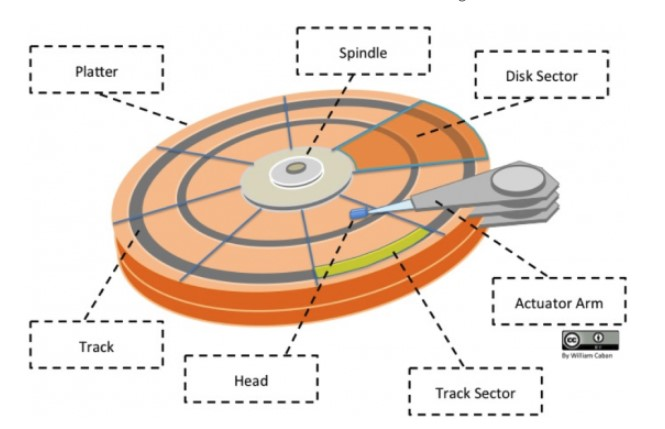
磁盘结构
盘面(Platter):一个磁盘有多个盘面;
磁道(Track):盘面上的圆形带状区域,一个盘面可以有多个磁道;
扇区(Track Sector):磁道上的一个弧段,一个磁道可以有多个扇区,它是最小的物理储存单位,目前主要有 512 bytes 与 4 K 两种大小;
磁头(Head):与盘面非常接近,能够将盘面上的磁场转换为电信号(读),或者将电信号转换为盘面的磁场(写);
制动手臂(Actuator arm):用于在磁道之间移动磁头;
主轴(Spindle):使整个盘面转动。
磁盘调度算法
读写一个磁盘块的时间的影响因素有:
旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)
寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
实际的数据传输时间
其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
- 先来先服务
FCFS, First Come First Served
按照磁盘请求的顺序进行调度。
优点是公平和简单。缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
- 最短寻道时间优先
SSTF, Shortest Seek Time First
优先调度与当前磁头所在磁道距离最近的磁道。
虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。
- 电梯算法
SCAN
电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘请求,然后改变方向。
因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。
针对电梯算法补充一些:
4.C-SCAN 循环扫描算法
会像SCAN算法一样从磁盘的一端到另一端,并且处理请求。而当到达另一端时会立即返回到开头,并不会处理回程上的请求,然后开始新一轮的一端到另一端。
5.LOOK
磁臂只移动到一个方向的最远请求为止,不会到末端。
这种模式的SCAN和C-SCAN称为LOOK和C-LOOK。
HTTP 状态码
| 状态码 | 类别 | 含义 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
- 1XX 信息
100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。 - 2XX 成功
200 OK
204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
- 3XX 重定向
301 Moved Permanently :永久性重定向
302 Found :临时性重定向
303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
注:虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会在 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
- 4XX 客户端错误
400 Bad Request :请求报文中存在语法错误。
401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
403 Forbidden :请求被拒绝。
404 Not Found
- 5XX 服务器错误
500 Internal Server Error :服务器正在执行请求时发生错误。
503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
HTTP 首部
有 4 种类型的首部字段:通用首部字段、请求首部字段、响应首部字段和实体首部字段。
各种首部字段及其含义如下(不需要全记,仅供查阅):
- 通用首部字段
首部字段名|说明
Cache-Control|控制缓存的行为
Connection|控制不再转发给代理的首部字段、管理持久连接
Date|创建报文的日期时间
Pragma|报文指令
Trailer|报文末端的首部一览
Transfer-Encoding|指定报文主体的传输编码方式
Upgrade|升级为其他协议
Via|代理服务器的相关信息
Warning|错误通知 - 请求首部字段
首部字段名|说明
Accept|用户代理可处理的媒体类型
Accept-Charset|优先的字符集
Accept-Encoding|优先的内容编码
Accept-Language|优先的语言(自然语言)
Authorization|Web 认证信息
Expect|期待服务器的特定行为
From|用户的电子邮箱地址
Host|请求资源所在服务器
If-Match|比较实体标记(ETag)
If-Modified-Since|比较资源的更新时间
If-None-Match|比较实体标记(与 If-Match 相反)
If-Range|资源未更新时发送实体 Byte 的范围请求
If-Unmodified-Since|比较资源的更新时间(与 If-Modified-Since 相反)
Max-Forwards|最大传输逐跳数
Proxy-Authorization|代理服务器要求客户端的认证信息
Range|实体的字节范围请求
Referer|对请求中 URI 的原始获取方
TE|传输编码的优先级
User-Agent|HTTP 客户端程序的信息 - 响应首部字段
首部字段名|说明
Accept-Ranges|是否接受字节范围请求
Age|推算资源创建经过时间
ETag|资源的匹配信息
Location|令客户端重定向至指定 URI
Proxy-Authenticate|代理服务器对客户端的认证信息
Retry-After|对再次发起请求的时机要求
Server|HTTP 服务器的安装信息
Vary|代理服务器缓存的管理信息
WWW-Authenticate|服务器对客户端的认证信息 - 实体首部字段
首部字段名|说明
Allow|资源可支持的 HTTP 方法
Content-Encoding|实体主体适用的编码方式
Content-Language|实体主体的自然语言
Content-Length|实体主体的大小
Content-Location|替代对应资源的 URI
Content-MD5|实体主体的报文摘要
Content-Range|实体主体的位置范围
Content-Type|实体主体的媒体类型
Expires|实体主体过期的日期时间
Last-Modified|资源的最后修改日期时间
会话期 Cookie:浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
持久性 Cookie:指定过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
HTTP 有以下安全性问题:
使用明文进行通信,内容可能会被窃听;
不验证通信方的身份,通信方的身份有可能遭遇伪装;
无法证明报文的完整性,报文有可能遭篡改。
HTTPS (全称:Hypertext Transfer Protocol Secure ),是以安全为目标的 HTTP 通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性 。
HTTPS 在HTTP 的基础下加入SSL,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。
HTTPS 存在不同于 HTTP 的默认端口及一个加密/身份验证层(在 HTTP与 TCP 之间)。这个系统提供了身份验证与加密通讯方法。它被广泛用于万维网上安全敏感的通讯,例如交易支付等方面 。
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
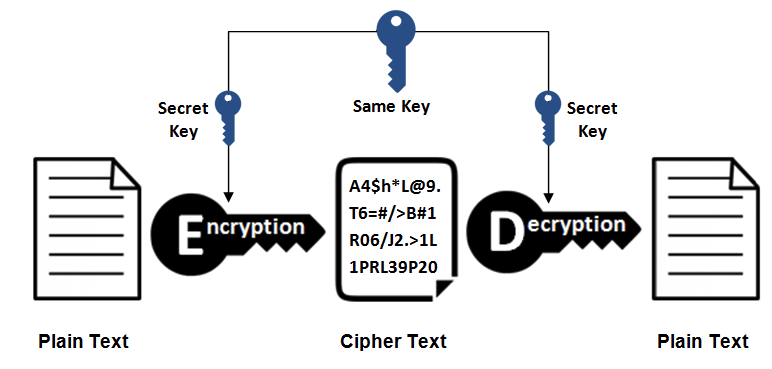
- 对称密钥加密
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
优点:运算速度快;
缺点:无法安全地将密钥传输给通信方。
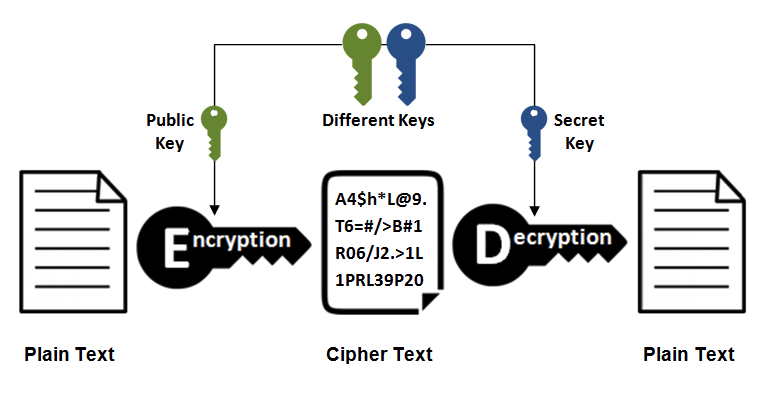
2.非对称密钥加密
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
优点:可以更安全地将公开密钥传输给通信发送方;
缺点:运算速度慢。
- HTTPS 采用的加密方式
上面提到对称密钥加密方式的传输效率更高,但是无法安全地将密钥 Secret Key 传输给通信方。而非对称密钥加密方式可以保证传输的安全性,因此我们可以利用非对称密钥加密方式将 Secret Key 传输给通信方。HTTPS 采用混合的加密机制,正是利用了上面提到的方案:
使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的 Session Key 就是 Secret Key)
通过使用 证书 来对通信方进行认证。
数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
服务器的运营人员向 CA 提出公开密钥的申请,CA 在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
数据库
SQL
基础
主键的值不允许修改,也不允许复用(不能将已经删除的主键值赋给新数据行的主键)。
SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL。各个 DBMS 都有自己的实现,如 PL/SQL、Transact-SQL 等。
SQL 语句不区分大小写,但是数据库表名、列名和值是否区分依赖于具体的 DBMS 以及配置。
SQL 支持以下三种注释:
1 | ## 注释 |
数据库创建与使用:
1 | CREATE DATABASE test; |
外模式(外部用户):决定用户的数据记录;
逻辑模式(数据库管理员):决定数据库内的逻辑结构;
内模式(系统程序员):决定数据库的物理存储结构。
创建表
1 | CREATE TABLE mytable ( |
为了防止建表的时候关键字重复,比如用max作为字段关键字的话,为了可读性需要加反引号
修改表
添加列
1 | ALTER TABLE mytable |
删除列
1 | ALTER TABLE mytable |
删除表
1 | DROP TABLE mytable; |
普通插入
1 | INSERT INTO mytable(col1, col2) |
插入检索出来的数据
1 | INSERT INTO mytable1(col1, col2) |
将一个表的内容插入到一个新表
1 | CREATE TABLE newtable AS |
更新
1 | UPDATE mytable |
update 表名 set 列名 = 新值 where 其他列 = 限定值
一次更新多个列
UPDATE mytable SET col1 = val1, col2 = val2 WHERE id = 1;
删除
1 | DELETE FROM mytable |
TRUNCATE TABLE 可以清空表,也就是删除所有行。
1 | TRUNCATE TABLE mytable; |
使用更新和删除操作时一定要用 WHERE 子句,不然会把整张表的数据都破坏。可以先用 SELECT 语句进行测试,防止错误删除。
TRUNCATE清除表的内容,但表还存在数据库
查询
DISTINCT
相同值只会出现一次。它作用于所有列,也就是说所有列的值都相同才算相同。
1 | SELECT DISTINCT col1, col2 |
LIMIT
限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。
返回前 5 行:
1 | SELECT * |
返回第 3 ~ 5 行:
1 | SELECT * |
“限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。”
所以 2 3是说从第2行开始起三行,是2-5行。
假设从sys_user表查询user_id的结果行数有6行。
1 | SELECT user_id |
现在我们需要限制返回的行数,比如需要返回从第3行至第5行的这三行记录,操作如下:
1 | # 写法一: |
排序
ASC :升序(默认)
DESC :降序
可以按多个列进行排序,并且为每个列指定不同的排序方式:
1 | SELECT * |
好像 asc 和 desc 语句需要在 limit 前面. 从逻辑上合理, 因为需要先排序, 然后再选取特别行数.
过滤
不进行过滤的数据非常大,导致通过网络传输了多余的数据,从而浪费了网络带宽。因此尽量使用 SQL 语句来过滤不必要的数据,而不是传输所有的数据到客户端中然后由客户端进行过滤。
1 | SELECT * |
下表显示了 WHERE 子句可用的操作符
操作符|说明
=|等于
<|小于
|大于
<> !=|不等于
<= !>|小于等于
= !<|大于等于
BETWEEN|在两个值之间
IS NULL|为 NULL 值
应该注意到,NULL 与 0、空字符串都不同。
AND 和 OR 用于连接多个过滤条件。优先处理 AND,当一个过滤表达式涉及到多个 AND 和 OR 时,可以使用 () 来决定优先级,使得优先级关系更清晰。
IN 操作符用于匹配一组值,其后也可以接一个 SELECT 子句,从而匹配子查询得到的一组值。
NOT 操作符用于否定一个条件。
通配符
通配符也是用在过滤语句中,但它只能用于文本字段。
% 匹配 >=0 个任意字符;
_ 匹配 ==1 个任意字符;
[ ] 可以匹配集合内的字符,例如 [ab] 将匹配字符 a 或者 b。用脱字符 ^ 可以对其进行否定,也就是不匹配集合内的字符。
使用 Like 来进行通配符匹配。
1 | SELECT * |
不要滥用通配符,通配符位于开头处匹配会非常慢。
MySQL 的 Like 只支持 %, -. 想用 [] 需要使用 Rlike 或 Regexp 并使用正则表达式.
通配位于开头会使索引失效
计算字段
在数据库服务器上完成数据的转换和格式化的工作往往比客户端上快得多,并且转换和格式化后的数据量更少的话可以减少网络通信量。
计算字段通常需要使用 AS 来取别名,否则输出的时候字段名为计算表达式。
1 | SELECT col1 * col2 AS alias |
CONCAT() 用于连接两个字段。许多数据库会使用空格把一个值填充为列宽,因此连接的结果会出现一些不必要的空格,使用 TRIM() 可以去除首尾空格。
1 | SELECT CONCAT(TRIM(col1), '(', TRIM(col2), ')') AS concat_col |
函数
各个 DBMS 的函数都是不相同的,因此不可移植,以下主要是 MySQL 的函数。
汇总
函 数 说 明
AVG() 返回某列的平均值
COUNT() 返回某列的行数
MAX() 返回某列的最大值
MIN() 返回某列的最小值
SUM() 返回某列值之和
AVG() 会忽略 NULL 行。
使用 DISTINCT 可以汇总不同的值。
1 | SELECT AVG(DISTINCT col1) AS avg_col |
文本处理
函数 说明
LEFT() 左边的字符
RIGHT() 右边的字符
LOWER() 转换为小写字符
UPPER() 转换为大写字符
LTRIM() 去除左边的空格
RTRIM() 去除右边的空格
LENGTH() 长度
SOUNDEX() 转换为语音值
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式。
1 | SELECT * |
日期和时间处理
日期格式:YYYY-MM-DD
时间格式:HH:
函 数 说 明
ADDDATE() 增加一个日期(天、周等)
ADDTIME() 增加一个时间(时、分等)
CURDATE() 返回当前日期
CURTIME() 返回当前时间
DATE() 返回日期时间的日期部分
DATEDIFF() 计算两个日期之差
DATE_ADD() 高度灵活的日期运算函数
DATE_FORMAT() 返回一个格式化的日期或时间串
DAY() 返回一个日期的天数部分
DAYOFWEEK() 对于一个日期,返回对应的星期几
HOUR() 返回一个时间的小时部分
MINUTE() 返回一个时间的分钟部分
MONTH() 返回一个日期的月份部分
NOW() 返回当前日期和时间
SECOND() 返回一个时间的秒部分
TIME() 返回一个日期时间的时间部分
YEAR() 返回一个日期的年份部分
1 | mysql> SELECT NOW(); |
数值处理
函数 说明
SIN() 正弦
COS() 余弦
TAN() 正切
ABS() 绝对值
SQRT() 平方根
MOD() 余数
EXP() 指数
PI() 圆周率
RAND() 随机数
ORM
即Object-Relational Mapping(对象关系映射),它的作用是在关系型数据库和业务实体对象之间作一个映射,这样,我们在具体的操作业务对象的时候,就不需要再去和复杂的SQL语句打交道,只需简单的操作对象的属性和方法。
实际工作中使用ORM提高开发效率,写SQL的机会也逐渐减少。
分组
把具有相同的数据值的行放在同一组中。
可以对同一分组数据使用汇总函数进行处理,例如求分组数据的平均值等。
指定的分组字段除了能按该字段进行分组,也会自动按该字段进行排序。
1 | SELECT col, COUNT(*) AS num |
GROUP BY 自动按分组字段进行排序,ORDER BY 也可以按汇总字段来进行排序。
1 | SELECT col, COUNT(*) AS num |
WHERE 过滤行,HAVING 过滤分组,行过滤应当先于分组过滤。
1 | SELECT col, COUNT(*) AS num |
分组规定:
GROUP BY 子句出现在 WHERE 子句之后,ORDER BY 子句之前;
除了汇总字段外,SELECT 语句中的每一字段都必须在 GROUP BY 子句中给出;
NULL 的行会单独分为一组;
大多数 SQL 实现不支持 GROUP BY 列具有可变长度的数据类型。
GROUP BY 子句出现在WHERE子句之后,ORDER BY 子句之前;
子查询
子查询中只能返回一个字段的数据。
可以将子查询的结果作为 WHRER 语句的过滤条件:
1 | SELECT * |
下面的语句可以检索出客户的订单数量,子查询语句会对第一个查询检索出的每个客户执行一次:
1 | SELECT cust_name, (SELECT COUNT(*) |
连接
连接用于连接多个表,使用 JOIN 关键字,并且条件语句使用 ON 而不是 WHERE。
连接可以替换子查询,并且比子查询的效率一般会更快。
可以用 AS 给列名、计算字段和表名取别名,给表名取别名是为了简化 SQL 语句以及连接相同表。
内连接
内连接又称等值连接,使用 INNER JOIN 关键字。
1 | SELECT A.value, B.value |
可以不明确使用 INNER JOIN,而使用普通查询并在 WHERE 中将两个表中要连接的列用等值方法连接起来。
1 | SELECT A.value, B.value |
自连接
自连接可以看成内连接的一种,只是连接的表是自身而已。
一张员工表,包含员工姓名和员工所属部门,要找出与 Jim 处在同一部门的所有员工姓名。
子查询版本
1 | SELECT name |
自连接版本
1 | SELECT e1.name |
自然连接
自然连接是把同名列通过等值测试连接起来的,同名列可以有多个。
内连接和自然连接的区别:内连接提供连接的列,而自然连接自动连接所有同名列。
1 | SELECT A.value, B.value |
外连接
外连接保留了没有关联的那些行。分为左外连接,右外连接以及全外连接,左外连接就是保留左表没有关联的行。
检索所有顾客的订单信息,包括还没有订单信息的顾客。
1 | SELECT Customers.cust_id, Customer.cust_name, Orders.order_id |
customers 表:
cust_id cust_name
1 a
2 b
3 c
orders 表:
order_id cust_id
1 1
2 1
3 3
4 3
结果:
cust_id cust_name order_id
1 a 1
1 a 2
3 c 3
3 c 4
2 b Null
组合查询
使用 UNION 来组合两个查询,如果第一个查询返回 M 行,第二个查询返回 N 行,那么组合查询的结果一般为 M+N 行。
每个查询必须包含相同的列、表达式和聚集函数。
默认会去除相同行,如果需要保留相同行,使用 UNION ALL。
只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
1 | SELECT col |
视图
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。
对视图的操作和对普通表的操作一样。
视图具有如下好处:
简化复杂的 SQL 操作,比如复杂的连接;
只使用实际表的一部分数据;
通过只给用户访问视图的权限,保证数据的安全性;
更改数据格式和表示。
1 | CREATE VIEW myview AS |
存储过程
存储过程可以看成是对一系列 SQL 操作的批处理。
使用存储过程的好处:
代码封装,保证了一定的安全性;
代码复用;
由于是预先编译,因此具有很高的性能。
命令行中创建存储过程需要自定义分隔符,因为命令行是以 ; 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。
补充一个缺点:
存储过程将复杂的业务逻辑封装进DB中,增加了维护成本。
包含 in、out 和 inout 三种参数。
给变量赋值都需要用 select into 语句。
每次只能给一个变量赋值,不支持集合的操作。
1 | delimiter // |
游标
在存储过程中使用游标可以对一个结果集进行移动遍历。
游标主要用于交互式应用,其中用户需要对数据集中的任意行进行浏览和修改。
使用游标的四个步骤:
声明游标,这个过程没有实际检索出数据;
打开游标;
取出数据;
关闭游标;
1 | delimiter // |
CREATE PROCEDURE pro_city()
BEGIN
定义三个变量,分别保存城市名、城市代码、城市人口
DECLARE row_name VARCHAR(20);
DECLARE row_code VARCHAR(20);
DECLARE row_pop INT;
定义游标
DECLARE getCity CURSOR FOR SELECT name, countrycode, population FROM city LIMIT 3;
打开游标
OPEN getCity;
从游标中取值
FETCH getCity INTO row_name, row_code, row_pop;
显示结果
SELECT row_name, row_code, row_pop;
CLOSE getCity;
END $
DELIMITER ; # 恢复 MySQL 的默认结束符
CALL pro_city();
触发器
触发器(trigger)是SQL server 提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它执行。触发器经常用于加强数据的完整性约束和业务规则等。
触发器会在某个表执行以下语句时而自动执行:DELETE、INSERT、UPDATE。
触发器必须指定在语句执行之前还是之后自动执行,之前执行使用 BEFORE 关键字,之后执行使用 AFTER 关键字。BEFORE 用于数据验证和净化,AFTER 用于审计跟踪,将修改记录到另外一张表中。
INSERT 触发器包含一个名为 NEW 的虚拟表。
不允许在触发器中使用存储过程
1 | CREATE TRIGGER mytrigger AFTER INSERT ON mytable |
DELETE 触发器包含一个名为 OLD 的虚拟表,并且是只读的。
UPDATE 触发器包含一个名为 NEW 和一个名为 OLD 的虚拟表,其中 NEW 是可以被修改的,而 OLD 是只读的。
MySQL 不允许在触发器中使用 CALL 语句,也就是不能调用存储过程。
事务管理
基本术语:
事务(transaction)指一组 SQL 语句;
回退(rollback)指撤销指定 SQL 语句的过程;
提交(commit)指将未存储的 SQL 语句结果写入数据库表;
保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
MySQL 的事务提交默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
设置 autocommit 为 0 可以取消自动提交;autocommit 标记是针对每个连接而不是针对服务器的。
如果没有设置保留点,ROLLBACK 会回退到 START TRANSACTION 语句处;如果设置了保留点,并且在 ROLLBACK 中指定该保留点,则会回退到该保留点。
1 | START TRANSACTION |
字符集
基本术语:
字符集为字母和符号的集合;
编码为某个字符集成员的内部表示;
校对字符指定如何比较,主要用于排序和分组。
除了给表指定字符集和校对外,也可以给列指定:
1 | CREATE TABLE mytable |
可以在排序、分组时指定校对:
1 | SELECT * |
权限管理
MySQL 的账户信息保存在 mysql 这个数据库中。
1 | USE mysql; |
创建账户
新创建的账户没有任何权限。
1 | CREATE USER myuser IDENTIFIED BY 'mypassword'; |
修改账户名
1 | RENAME USER myuser TO newuser; |
删除账户
1 | DROP USER myuser; |
查看权限
1 | SHOW GRANTS FOR myuser; |
授予权限
账户用 username@host 的形式定义,username@% 使用的是默认主机名。
1 | GRANT SELECT, INSERT ON mydatabase.* TO myuser; |
删除权限
GRANT 和 REVOKE 可在几个层次上控制访问权限:
整个服务器,使用 GRANT ALL 和 REVOKE ALL;
整个数据库,使用 ON database.*;
特定的表,使用 ON database.table;
特定的列;
特定的存储过程。
1 | REVOKE SELECT, INSERT ON mydatabase.* FROM myuser; |
更改密码
必须使用 Password() 函数进行加密。
1 | SET PASSWROD FOR myuser = Password('new_password'); |
数据库系统原理
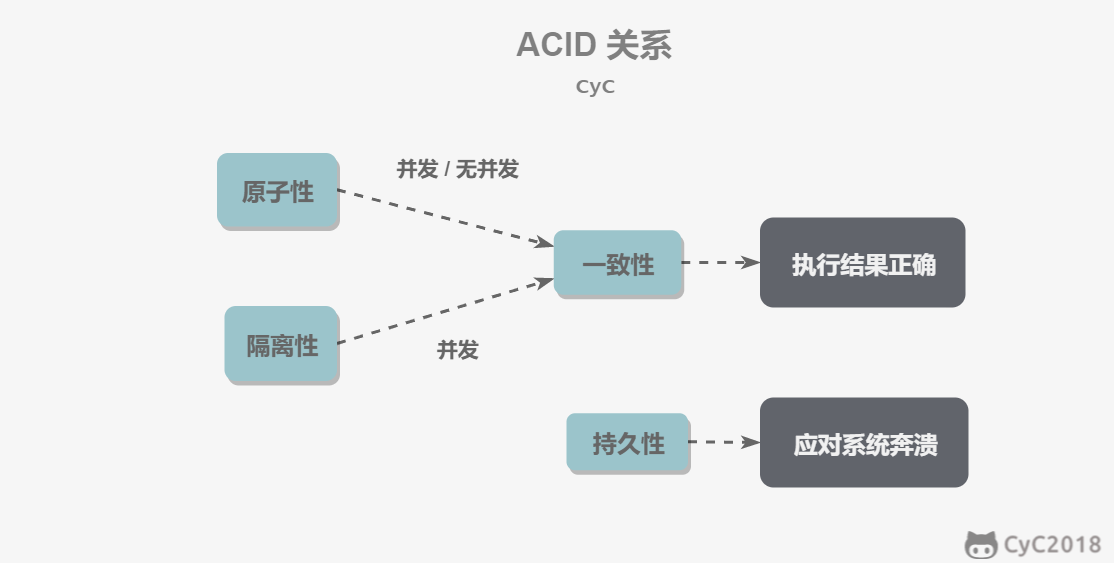
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
ACID
- 原子性(Atomicity)
事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚。
回滚可以用回滚日志(Undo Log)来实现,回滚日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。
一致性(Consistency)
数据库在事务执行前后都保持一致性状态。在一致性状态下,所有事务对同一个数据的读取结果都是相同的。隔离性(Isolation)
一个事务所做的修改在最终提交以前,对其它事务是不可见的。持久性(Durability)
一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
系统发生崩溃可以用重做日志(Redo Log)进行恢复,从而实现持久性。与回滚日志记录数据的逻辑修改不同,重做日志记录的是数据页的物理修改。
事务的 ACID 特性概念简单,但不是很好理解,主要是因为这几个特性不是一种平级关系:
只有满足一致性,事务的执行结果才是正确的。
在无并发的情况下,事务串行执行,隔离性一定能够满足。此时只要能满足原子性,就一定能满足一致性。
在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
事务满足持久化是为了能应对系统崩溃的情况。
AUTOCOMMIT
MySQL 默认采用自动提交模式。也就是说,如果不显式使用 START TRANSACTION 语句来开始一个事务,那么每个查询操作都会被当做一个事务并自动提交。
现实中分布式一致性场景
我们来看一下几个典型的分布式一致性场景
1、银行转账
在跨行转账过程中,我们经常会遇到这种情况:我本行的money已经扣除成功,但是对方银行入账可能需要在N个工作日后到账!此时我们一般不担心钱丢失问题:只要在给定的期限内到账且钱不要少就好了!—-这也成为了几乎所有用户对于现代银行系统最基本的需求
2、火车购票
K1314次列车,深圳-北京的卧铺仅剩下最后一张车票了,可能在同一时刻,有很多乘客在不同地点的不同售票窗口都想买这一张车票,但是这张票只会卖给一位用户,这就需要购票系统的每一个节点都要有强一致的剩余车票数据
3、网上购物
我们经常会看到某个秒杀物品会在页面上展示商品的剩余数量,其实大家都知道这个数量绝大多数是缓存数据,不是实时更新的,但是在某一段时间后会同步最终剩余数量。
封锁粒度
MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。
但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。
在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
封锁类型
- 读写锁
互斥锁(Exclusive),简写为 X 锁,又称写锁。
共享锁(Shared),简写为 S 锁,又称读锁。
有以下两个规定:
一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
锁的兼容关系如下:

- 意向锁
使用意向锁(Intention Locks)可以更容易地支持多粒度封锁。
在存在行级锁和表级锁的情况下,事务 T 想要对表 A 加 X 锁,就需要先检测是否有其它事务对表 A 或者表 A 中的任意一行加了锁,那么就需要对表 A 的每一行都检测一次,这是非常耗时的。
意向锁在原来的 X/S 锁之上引入了 IX/IS,IX/IS 都是表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S 锁。有以下两个规定:
一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
通过引入意向锁,事务 T 想要对表 A 加 X 锁,只需要先检测是否有其它事务对表 A 加了 X/IX/S/IS 锁,如果加了就表示有其它事务正在使用这个表或者表中某一行的锁,因此事务 T 加 X 锁失败。
各种锁的兼容关系如下:

解释如下:
任意 IS/IX 锁之间都是兼容的,因为它们只表示想要对表加锁,而不是真正加锁;
这里兼容关系针对的是表级锁,而表级的 IX 锁和行级的 X 锁兼容,两个事务可以对两个数据行加 X 锁。(事务
T1想要对数据行R1加 X 锁,事务T2想要对同一个表的数据行R2加 X 锁,两个事务都需要对该表加 IX 锁,但是 IX 锁是兼容的,并且 IX 锁与行级的 X 锁也是兼容的,因此两个事务都能加锁成功,对同一个表中的两个数据行做修改。)
封锁协议
- 三级封锁协议
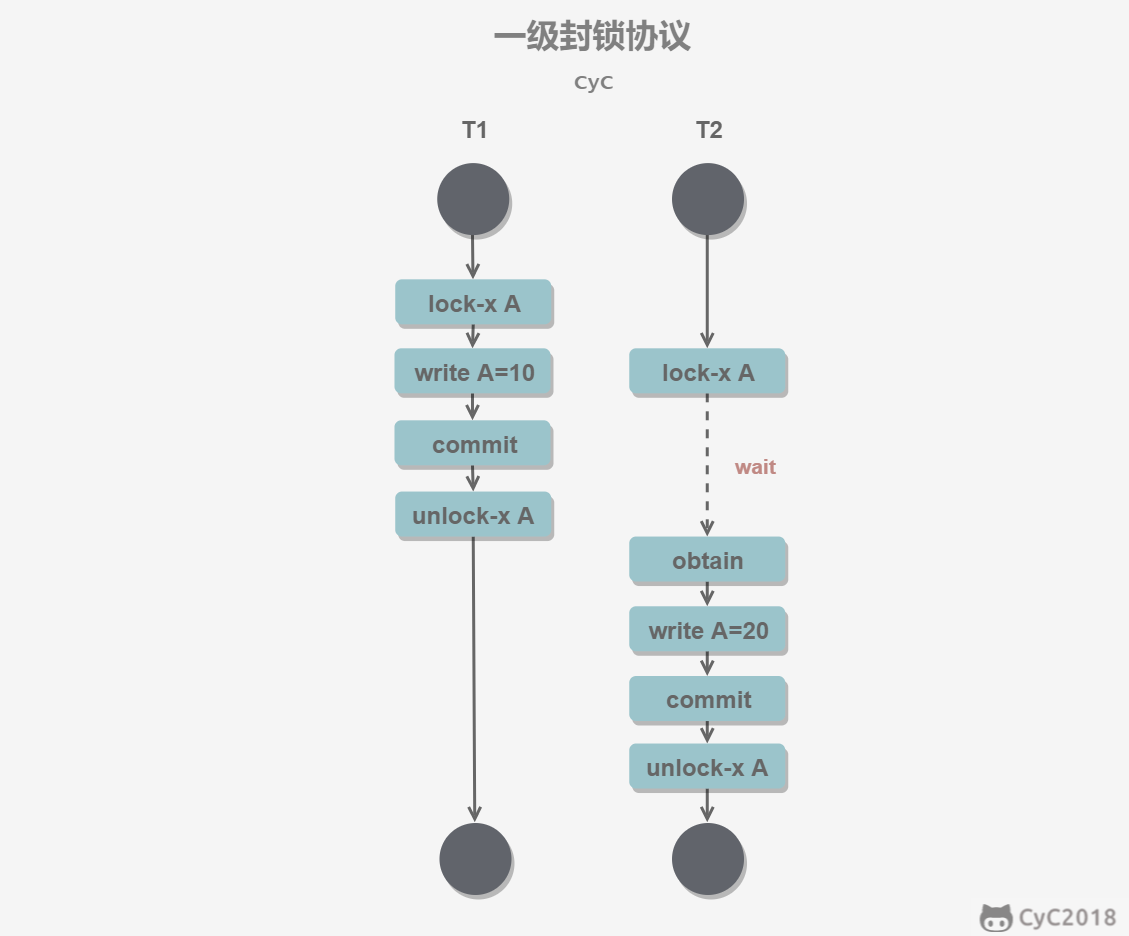
一级封锁协议
事务 T 要修改数据 A 时必须加 X 锁,直到 T 结束才释放锁。
可以解决丢失修改问题,因为不能同时有两个事务对同一个数据进行修改,那么事务的修改就不会被覆盖。
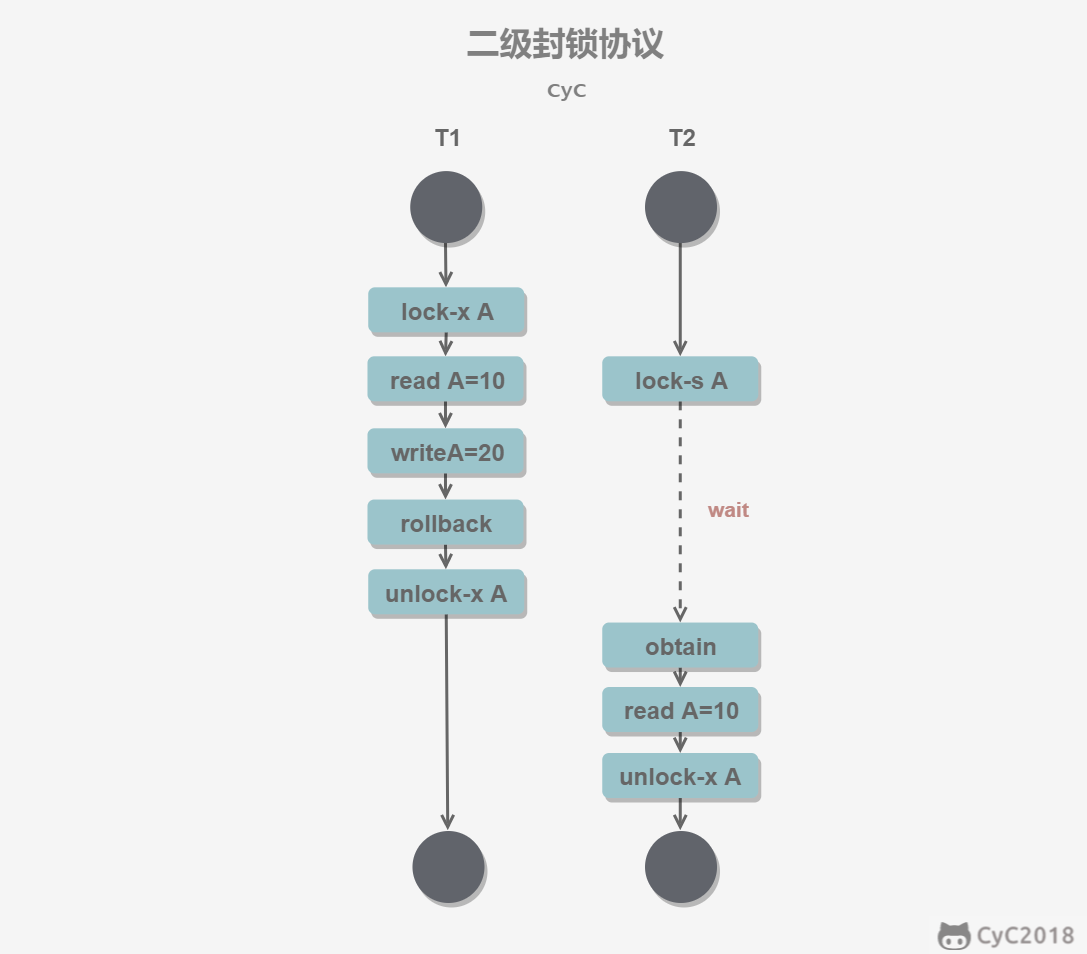
二级封锁协议
在一级的基础上,要求读取数据 A 时必须加 S 锁,读取完马上释放 S 锁。
可以解决读脏数据问题,因为如果一个事务在对数据 A 进行修改,根据 1 级封锁协议,会加 X 锁,那么就不能再加 S 锁了,也就是不会读入数据。
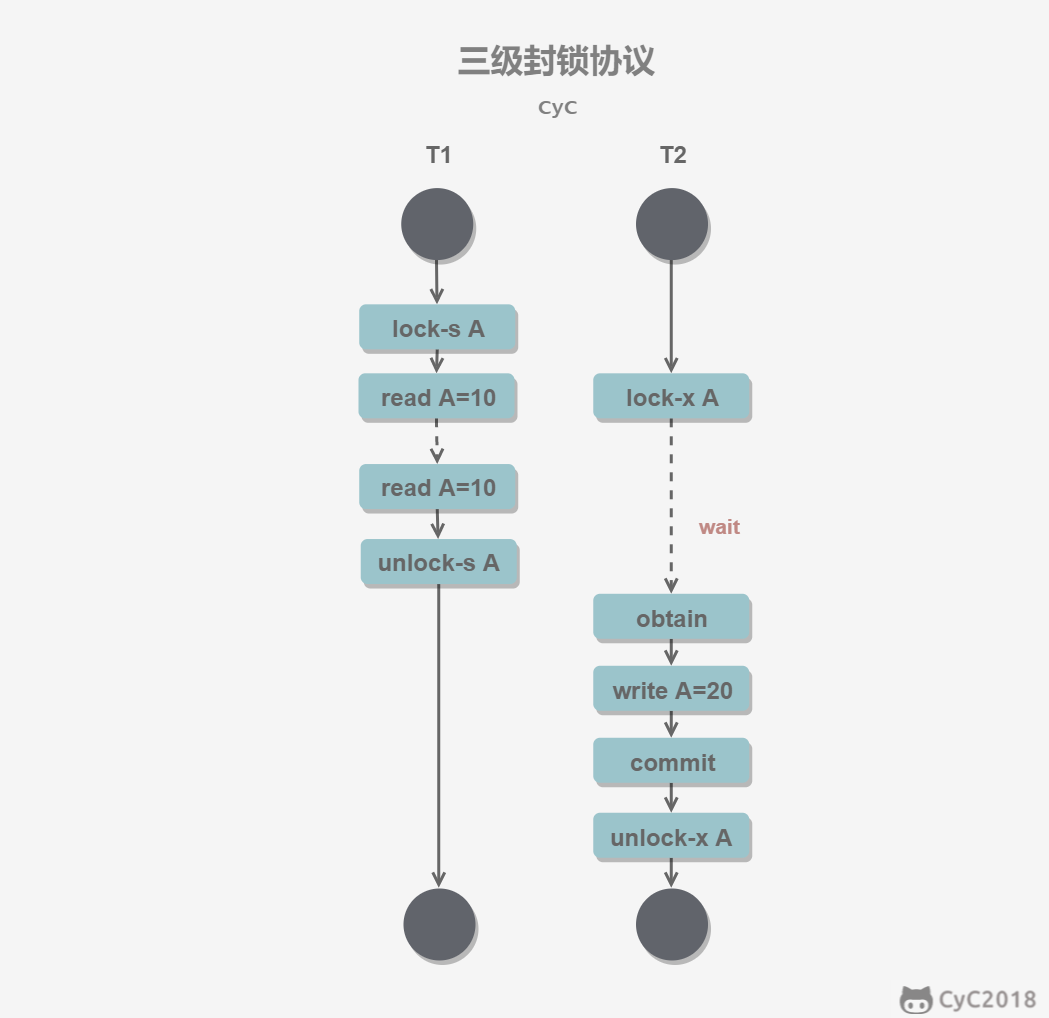
三级封锁协议
在二级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。
可以解决不可重复读的问题,因为读 A 时,其它事务不能对 A 加 X 锁,从而避免了在读的期间数据发生改变。
- 两段锁协议
加锁和解锁分为两个阶段进行。
可串行化调度是指,通过并发控制,使得并发执行的事务结果与某个串行执行的事务结果相同。串行执行的事务互不干扰,不会出现并发一致性问题。
事务遵循两段锁协议是保证可串行化调度的充分条件。例如以下操作满足两段锁协议,它是可串行化调度。
lock-x(A)…lock-s(B)…lock-s(C)…unlock(A)…unlock(C)…unlock(B)
但不是必要条件,例如以下操作不满足两段锁协议,但它还是可串行化调度。
lock-x(A)…unlock(A)…lock-s(B)…unlock(B)…lock-s(C)…unlock(C)
MySQL 隐式与显示锁定
MySQL 的 InnoDB 存储引擎采用两段锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被称为隐式锁定。
InnoDB 也可以使用特定的语句进行显示锁定:
1 | SELECT ... LOCK In SHARE MODE; |
X 完全封禁,封条标志。
S Share,分享,可以读,但不能改。
X S 加在行上的锁
IX IS 加在表上的锁
隔离级别
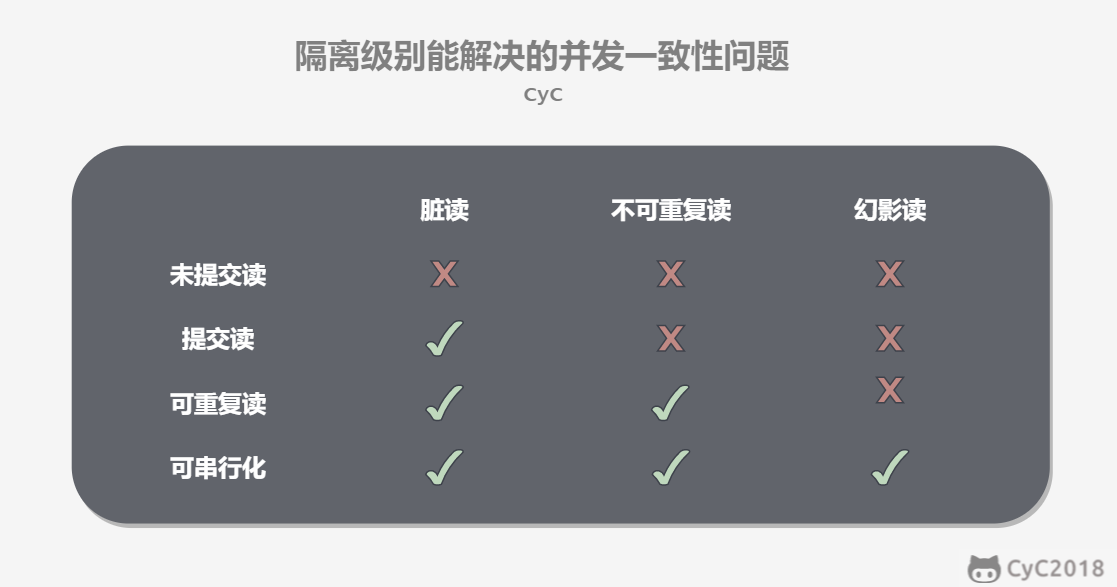
未提交读(READ UNCOMMITTED)
事务中的修改,即使没有提交,对其它事务也是可见的。
提交读(READ COMMITTED)
一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
可重复读(REPEATABLE READ)
保证在同一个事务中多次读取同一数据的结果是一样的。
可串行化(SERIALIZABLE)
强制事务串行执行,这样多个事务互不干扰,不会出现并发一致性问题。
该隔离级别需要加锁实现,因为要使用加锁机制保证同一时间只有一个事务执行,也就是保证事务串行执行。
多版本并发控制(Multi-Version Concurrency Control, MVCC)是 MySQL 的 InnoDB 存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,要求很低,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
基本思想
在封锁一节中提到,加锁能解决多个事务同时执行时出现的并发一致性问题。在实际场景中读操作往往多于写操作,因此又引入了读写锁来避免不必要的加锁操作,例如读和读没有互斥关系。读写锁中读和写操作仍然是互斥的,而 MVCC 利用了多版本的思想,写操作更新最新的版本快照,而读操作去读旧版本快照,没有互斥关系,这一点和 CopyOnWrite 类似。
在 MVCC 中事务的修改操作(DELETE、INSERT、UPDATE)会为数据行新增一个版本快照。
脏读和不可重复读最根本的原因是事务读取到其它事务未提交的修改。在事务进行读取操作时,为了解决脏读和不可重复读问题,MVCC 规定只能读取已经提交的快照。当然一个事务可以读取自身未提交的快照,这不算是脏读。
版本号
系统版本号 SYS_ID:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
事务版本号 TRX_ID :事务开始时的系统版本号。
Undo 日志
MVCC 的多版本指的是多个版本的快照,快照存储在 Undo 日志中,该日志通过回滚指针 ROLL_PTR 把一个数据行的所有快照连接起来。
例如在 MySQL 创建一个表 t,包含主键 id 和一个字段 x。我们先插入一个数据行,然后对该数据行执行两次更新操作。
1 | INSERT INTO t(id, x) VALUES(1, "a"); |
因为没有使用 START TRANSACTION 将上面的操作当成一个事务来执行,根据 MySQL 的 AUTOCOMMIT 机制,每个操作都会被当成一个事务来执行,所以上面的操作总共涉及到三个事务。快照中除了记录事务版本号 TRX_ID 和操作之外,还记录了一个 bit 的 DEL 字段,用于标记是否被删除。
快照读与当前读
- 快照读
MVCC 的 SELECT 操作是快照中的数据,不需要进行加锁操作。
1 | SELECT * FROM table ...; |
- 当前读
MVCC 其它会对数据库进行修改的操作(INSERT、UPDATE、DELETE)需要进行加锁操作,从而读取最新的数据。可以看到 MVCC 并不是完全不用加锁,而只是避免了 SELECT 的加锁操作。
1 | INSERT; |
在进行 SELECT 操作时,可以强制指定进行加锁操作。以下第一个语句需要加 S 锁,第二个需要加 X 锁。
1 | SELECT * FROM table WHERE ? lock in share mode; |
解决脏读,不可重复读使用MVCC来实现
解决幻读,MVCC+Next-Key Locks
Next-Key Locks锁住一条记录的索引,还会锁住索引之间的间隙
MVCC+Next-Key Locks解决幻读问题
Next-Key Locks
Next-Key Locks 是 MySQL 的 InnoDB 存储引擎的一种锁实现。
MVCC 不能解决幻影读问题,Next-Key Locks 就是为了解决这个问题而存在的。在可重复读(REPEATABLE READ)隔离级别下,使用 MVCC + Next-Key Locks 可以解决幻读问题。
Record Locks
锁定一个记录上的索引,而不是记录本身。
如果表没有设置索引,InnoDB 会自动在主键上创建隐藏的聚簇索引,因此 Record Locks 依然可以使用。
Gap Locks
锁定索引之间的间隙,但是不包含索引本身。例如当一个事务执行以下语句,其它事务就不能在 t.c 中插入 15。
1 | SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE; |
Next-Key Locks
它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间,例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
1 | (-∞, 10] |
关系数据库设计理论
函数依赖
记 A->B 表示 A 函数决定 B,也可以说 B 函数依赖于 A。
如果 {A1,A2,… ,An} 是关系的一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
对于 A->B,如果能找到 A 的真子集 A’,使得 A’-> B,那么 A->B 就是部分函数依赖,否则就是完全函数依赖。
对于 A->B,B->C,则 A->C 是一个传递函数依赖。
异常
以下的学生课程关系的函数依赖为 {Sno, Cname} -> {Sname, Sdept, Mname, Grade},键码为 {Sno, Cname}。也就是说,确定学生和课程之后,就能确定其它信息。
Sno Sname Sdept Mname Cname Grade
1 学生-1 学院-1 院长-1 课程-1 90
2 学生-2 学院-2 院长-2 课程-2 80
2 学生-2 学院-2 院长-2 课程-1 100
3 学生-3 学院-2 院长-2 课程-2 95
不符合范式的关系,会产生很多异常,主要有以下四种异常:
冗余数据:例如 学生-2 出现了两次。
修改异常:修改了一个记录中的信息,但是另一个记录中相同的信息却没有被修改。
删除异常:删除一个信息,那么也会丢失其它信息。例如删除了 课程-1 需要删除第一行和第三行,那么 学生-1 的信息就会丢失。
插入异常:例如想要插入一个学生的信息,如果这个学生还没选课,那么就无法插入。
范式
范式理论是为了解决以上提到四种异常。
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
- 第一范式 (1NF)
属性不可分。 - 第二范式 (2NF)
每个非主属性完全函数依赖于键码。
可以通过分解来满足。
分解前
Sno Sname Sdept Mname Cname Grade
1 学生-1 学院-1 院长-1 课程-1 90
2 学生-2 学院-2 院长-2 课程-2 80
2 学生-2 学院-2 院长-2 课程-1 100
3 学生-3 学院-2 院长-2 课程-2 95
以上学生课程关系中,{Sno, Cname} 为键码,有如下函数依赖:
Sno -> Sname, Sdept
Sdept -> Mname
Sno, Cname-> Grade
Grade 完全函数依赖于键码,它没有任何冗余数据,每个学生的每门课都有特定的成绩。
Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门课时,这些数据就会出现多次,造成大量冗余数据。
分解后
关系-1
Sno Sname Sdept Mname
1 学生-1 学院-1 院长-1
2 学生-2 学院-2 院长-2
3 学生-3 学院-2 院长-2
有以下函数依赖:
Sno -> Sname, Sdept
Sdept -> Mname
关系-2
Sno Cname Grade
1 课程-1 90
2 课程-2 80
2 课程-1 100
3 课程-2 95
有以下函数依赖:
Sno, Cname -> Grade
3. 第三范式 (3NF)
非主属性不传递函数依赖于键码。
上面的 关系-1 中存在以下传递函数依赖:
Sno -> Sdept -> Mname
可以进行以下分解:
关系-11
Sno Sname Sdept
1 学生-1 学院-1
2 学生-2 学院-2
3 学生-3 学院-2
关系-12
Sdept Mname
学院-1 院长-1
学院-2 院长-2
ER 图
Entity-Relationship,有三个组成部分:实体、属性、联系。
用来进行关系型数据库系统的概念设计。
实体的三种联系
包含一对一,一对多,多对多三种。
如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B;
如果是一对一,画两个带箭头的线段;
如果是多对多,画两个不带箭头的线段。
表示出现多次的关系
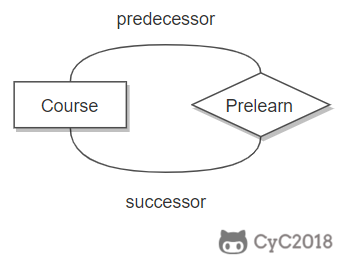
一个实体在联系出现几次,就要用几条线连接。
下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。
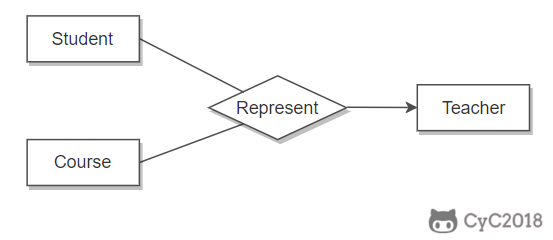
联系的多向性
虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。
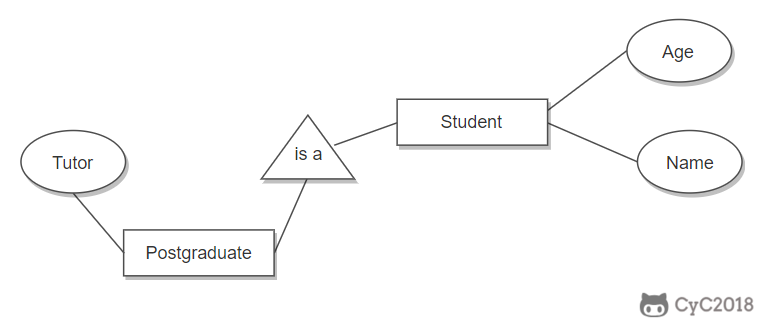
表示子类
用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。
MySQL
MySQL 索引
索引优化
- 独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
1 | SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5; |
- 多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 film_id 设置为多列索引。
1 | SELECT film_id, actor_ id FROM sakila.film_actor |
- 索引列的顺序
让选择性最强的索引列放在前面。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
1 | SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, |
- 前缀索引
对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
前缀长度的选取需要根据索引选择性来确定。
- 覆盖索引
索引包含所有需要查询的字段的值。
具有以下优点:
索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
查询性能优化
使用 Explain 进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
select_type : 查询类型,有简单查询、联合查询、子查询等
key : 使用的索引
rows : 扫描的行数
优化数据访问
- 减少请求的数据量
只返回必要的列:最好不要使用 SELECT * 语句。
只返回必要的行:使用 LIMIT 语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。 - 减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
重构查询方式
- 切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
1 | DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH); |
- 分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
减少锁竞争;
在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
1 | SELECT * FROM tag |
存储引擎
InnoDB
是 MySQL 默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。
实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ Next-Key Locking 防止幻影读。
主索引是聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,因此对查询性能有很大的提升。
内部做了很多优化,包括从磁盘读取数据时采用的可预测性读、能够加快读操作并且自动创建的自适应哈希索引、能够加速插入操作的插入缓冲区等。
支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取。
MyISAM
设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用它。
提供了大量的特性,包括压缩表、空间数据索引等。
不支持事务。
不支持行级锁,只能对整张表加锁,读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但在表有读取操作的同时,也可以往表中插入新的记录,这被称为并发插入(CONCURRENT INSERT)。
可以手工或者自动执行检查和修复操作,但是和事务恢复以及崩溃恢复不同,可能导致一些数据丢失,而且修复操作是非常慢的。
如果指定了 DELAY_KEY_WRITE 选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作。
比较
事务:InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句。
并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
外键:InnoDB 支持外键。
备份:InnoDB 支持在线热备份。
崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
其它特性:MyISAM 支持压缩表和空间数据索引。
数据类型
整型
TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 分别使用 8, 16, 24, 32, 64 位存储空间,一般情况下越小的列越好。
INT(11) 中的数字只是规定了交互工具显示字符的个数,对于存储和计算来说是没有意义的。
浮点数
FLOAT 和 DOUBLE 为浮点类型,DECIMAL 为高精度小数类型。CPU 原生支持浮点运算,但是不支持 DECIMAl 类型的计算,因此 DECIMAL 的计算比浮点类型需要更高的代价。
FLOAT、DOUBLE 和 DECIMAL 都可以指定列宽,例如 DECIMAL(18, 9) 表示总共 18 位,取 9 位存储小数部分,剩下 9 位存储整数部分。
字符串
主要有 CHAR 和 VARCHAR 两种类型,一种是定长的,一种是变长的。
VARCHAR 这种变长类型能够节省空间,因为只需要存储必要的内容。但是在执行 UPDATE 时可能会使行变得比原来长,当超出一个页所能容纳的大小时,就要执行额外的操作。MyISAM 会将行拆成不同的片段存储,而 InnoDB 则需要分裂页来使行放进页内。
在进行存储和检索时,会保留 VARCHAR 末尾的空格,而会删除 CHAR 末尾的空格。
时间和日期
MySQL 提供了两种相似的日期时间类型:DATETIME 和 TIMESTAMP。
- DATETIME
能够保存从 1000 年到 9999 年的日期和时间,精度为秒,使用 8 字节的存储空间。
它与时区无关。
默认情况下,MySQL 以一种可排序的、无歧义的格式显示 DATETIME 值,例如“2008-01-16 22:37:08”,这是 ANSI 标准定义的日期和时间表示方法。
- TIMESTAMP
和 UNIX 时间戳相同,保存从 1970 年 1 月 1 日午夜(格林威治时间)以来的秒数,使用 4 个字节,只能表示从 1970 年到 2038 年。
它和时区有关,也就是说一个时间戳在不同的时区所代表的具体时间是不同的。
MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提供了 UNIX_TIMESTAMP() 函数把日期转换为 UNIX 时间戳。
默认情况下,如果插入时没有指定 TIMESTAMP 列的值,会将这个值设置为当前时间。
应该尽量使用 TIMESTAMP,因为它比 DATETIME 空间效率更高。
水平切分
水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
垂直切分
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
Sharding 策略
- 哈希取模:hash(key) % N;
- 范围:可以是 ID 范围也可以是时间范围;
- 映射表:使用单独的一个数据库来存储映射关系。
Sharding 存在的问题
事务问题
使用分布式事务来解决,比如 XA 接口。连接
可以将原来的连接分解成多个单表查询,然后在用户程序中进行连接。ID 唯一性
使用全局唯一 ID(GUID)
为每个分片指定一个 ID 范围
分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)
主从复制
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
I/O 线程 :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
SQL 线程 :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
读写分离能提高性能的原因在于:
主从服务器负责各自的读和写,极大程度缓解了锁的争用;
从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
增加冗余,提高可用性。
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
Linux 的系统调用主要有以下这些:
Task|Commands
进程控制|fork(); exit(); wait();
进程通信|pipe(); shmget(); mmap();
文件操作|open(); read(); write();
设备操作|ioctl(); read(); write();
信息维护|getpid(); alarm(); sleep();
安全|chmod(); umask(); chown();
编程常识
跨平台的编程语言都需要做内存对齐。
为什么会有内存对齐?
平台原因:不是所有的硬件平台都能访问任意内存地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。为了同一个程序可以在多平台运行,需要内存对齐。
硬件原因:经过内存对齐后,CPU 访问内存的速度大大提升。
简历
① 基本信息:姓名、手机、邮箱、求职意向、年龄、居住地、求职照可酌情提供
② 教育背景:建议列出优秀绩点和排名;实验室履历或师从著名导师
③ 工作/实习经历:公司、岗位及工作内容和成果
④ 科研/项目经历:发表论文、 取得专利、 参加比赛及参与的业务项目;体现专业、科研、 思维、解决问题能力
⑤ 荣誉/获奖经历:奖学金、 荣誉称号、学科竞赛、 学术竞赛、 创业竞赛、 编程竞赛
⑥ 组织/社团经历:参与的学生组织、 担任的职位、 工作内容及成果;体现领导能力、 沟通力和实践能力
⑦ 其他:个人评价、技能证书、 技能等级
企业关注顺序:
经历:工作、实习、科研、项目
学历、学校
专业技能:与岗位匹配的软/硬技能,语言技能
荣誉:证书
业余爱好:健身、游泳、羽毛球
快速聚焦的关键词:
全系排名、最高XX
可熟练使用、掌握语言技能
优秀毕业生、优秀实习生、国家奖学金
精通、擅长、掌握、熟悉、负责、参与
环境:时间、地点、起因、具体问题「项目背景,强调项目的重要性」
任务:完成的任务「项目目标,尽可能用数据量化,做到什么样的程度则代表成功」
行动:使用/选择/采用X方法工具「不需要面面俱到,应重点描述里程碑式事件,突出短时间高效益」
结果:做到了什么,认知「结果与目标对比以体现是否成功。交代自己的贡献度,是带领团队一起,还是在团队中扮演某个角色去完成的。」
应描述实际行为,而非个人观点
应描述自己的行为,而非他人的行为
应描述具体事件,而非概括总结
了解岗位的招聘诉求
扩充团队:要求求职者能快速上手投入工作,培养周期偏短,对应聘者的过往经历、背景、能力要求比较高
补齐能力:求职者的能力是否刚好吻合岗位当前所缺
培养梯队:指培养接班人,如管培生,除了看中求职者当前与岗位的适配度之外,更关注其成长性以及综合素养。
面试官提问:如果重新负责某项工作,你会如何思考并改进?
建议在重点描述的经历里, 增加对于此类经历的复盘和反思。
展现并突出自己能够保障有效落地、规避落地风险的品质,比如聪明、乐观、皮实、自信等特质。
词语的强烈程度:精通 > 熟悉> 掌握> 了解
了解,熟悉,掌握,熟练,精通
专业技能
扩展细化,缩小面试提问范围
熟悉 C++,(列举C++的若干知识点,熟练使用C的指针应用及内存管理,C++的封装继承多态,STL常用容器,C++11常用特性(智能指针等)),掌握 Go(),了解 Java,python 等(适当补充对这些语言的理解)
熟悉 linux 操作系统常用命令,vim 开发环境,(列举网络编程相关知识,例如 epoll,socket 等)
了解框架 ……
熟悉网络,(列举网络协议相关考点,tcp/ip,http, https, 三次,四次握手,流量控制等等)
掌握基础数据结构和算法
项目经历
记录思路,挖掘亮点、难点
公司 - xx服务器 - 独立开发 - 201508- 201512
- 具体功能
- 运用了那些技术,技术难点是
- 效果如何
- demo演示地址,github地址
分「项目描述」「个人工作」「项目亮点/难点/个人收获」三块来写
面试
一面机试:一般会考选择题和编程题
二面基础算法面:就是基础的算法都是该专栏要讲的,白纸代码
三面综合技术面:会考察编程语言,计算机基础知识,以及了解项目经历(技术原理、 技术深度、应变能力)
四面技术boss面:会问一些比较范范的内容,考察大家解决问题和快速学习的能力
解决问题的能力
面试官最喜欢问的相关问题:
在项目中遇到的最大的技术挑战是什么,而你是如果解决的
给出一个项目问题来让面试者分析
快速学习的能力
面试官最喜欢问的相关问题:
快速学习的能力 如果快速学习一门新的技术或者语言?
总结一下自己学习的技巧
读研之后发现自己和本科毕业有什么差别?
这里要体现出自己思维方式和学习方法上的进步,而不是用了两三年的时间有多学了那些技术,因为互联网是不断变化的。
最后hr面:主要了解面试者与企业文化相不相符,面试者的职业发展,offer的选择以及介绍一下企业提供的薪资待遇等等
为什么选择我们公司?
这个大家一定要有所准备,不能被问到了之后一脸茫然,然后说 就是想找个工作,那基本就没戏了
要从技术氛围,职业发展,公司潜力等等方面来说自己为什么选择这家公司
#有没有职业规划?
其实如果刚刚毕业并没有明确的职业规划,这里建议大家不要说 自己想工作几年想做项目经理,工作几年想做产品经理的
这样会被HR认为 职业规划不清晰,尽量从技术的角度规划自己。
#是否接受加班?
虽然大家都不喜欢加班,但是这个问题 我还是建议如果手头没有offer的话,大家尽量选择接受了
#坚持最长的一件事情是什么?
这里大家最好之前就想好,有一些同学可能印象里自己没有坚持很长的事情,也没有好好想过这个问题,在HR面的时候被问到的时候,一脸茫然
憋了半天说出一个不痛不痒的事情。这就是一个减分项了
#如果校招,直接会问:期望薪资XXX是否接受?
这里大家如果感觉自己表现的很好 给面试官留下的很好的印象,可以在这里争取 special offer,或者ssp offer
这都是可以的,但是要真的对自己信心十足。
#如果社招,则会了解前一家目前公司薪水多少 ?
这里大家切记不要虚报工资,因为入职前是要查流水的,这个是比较严肃的问题。
介绍一下公司薪酬福利待遇
面试技巧
与面试官交流,准备纸笔,讲清思路怎么来的,对题目的描述、关键点和细节追问,包括询问数据的范围
先说暴力解法,再说优化解法
说解法后再说复杂度,得到面试官确认后在再写代码
Other
七张图片转换成目录
Refer
热招技术岗上岸指南
暑期实习岗位攻略
春招热门岗位攻略
校招基础知识详解
求职突破一本通【校招版】
代码随想录-最强八股文-第3版
《用面试官的思维写简历》
招聘信息里对技术的要求有“了解”、“熟悉”、“精通”,该怎么界定?
校招时间节点、简历编写、笔试、HR面、实习等注意事项💪