Pref
主要整理 SQL 语言,其次是 DBMS 等数据库知识,求职必备啊,欠下的知识迟早要补上,往后定要化被动为主动,学得太赶了,头秃……
Basis
数据库(database)保存有组织的数据的容器(通常是一个或一组文件)
表(table)某种特定类型数据的结构化清单。
模式(schema)关于数据库和表的布局及特性的信息。
列(column)表中的一个字段。表都是由一个或多个列组成的。
数据类型(datatype)定义了列可以存储哪些数据种类。
行(row)表中的一个记录。也称记录(record),行才是正确术语。
主键(primary key)一列或几列,其值能够唯一标识表中每一行。
注:应总是定义主键,可能不需要,但保证创建的每个表具有一个主键,便于以后的数据操作管理。
满足条件:
- 任意两行都不具有相同的主键值;
- 每一行都必须具有一个主键值(主键列不允许空值 NULL);
- 主键列中的值不允许修改或更新;
- 主键值不能重用(若某行从表中删除,其主键不能再赋给新行)
SQL(发音 sequel)(Structured Query Language)结构化查询语言。
多条 SQL 语句必须以分号(;)分隔,部分 DBMS 需要单条语句后都加。
SQL 语句不区分大小写。
处理 SQL 语句时,空格都被忽略。
SQL 语句一般返回无格式的数据。
子句(clause)SQL 语句由子句构成。一个子句通常由一个关键字加上所提供的数据组成。
可移植(portable)可在多个系统上运行。
查询(query)任何 SQL 语句都是查询。但一般指 SELECT 语句。
子查询(subquery)即嵌套在其他查询中的查询。
结果集(result set)SQL 查询所检索出的结果。
检索数据
检索单个列
1 | SELECT prod_name |
从 Products 表中检索 prod_name 列。

根据具体 DBMS 和客户端,会得出检索行数和时间。
如 MySQL——9 rows in set (0.01 sec)
检索多个列
选择多列时,列名之间加逗号,最后一个不加,否则报错。
1 | SELECT prod_id, prod_name, prod_price |
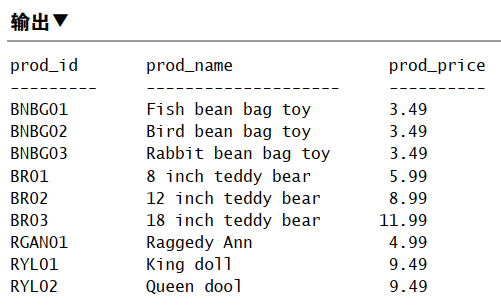
检索所有列
1 | SELECT * |
检索不同值
1 | SELECT vend_id |

返回 9 行(即使表中只有 3 个产品供应商),因为 Products 表中有 9 种产品。
DISTINCT 关键字,指示数据库只返回不同的值。
1 | SELECT DISTINCT vend_id |
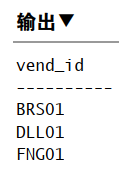
注:不能部分使用 DISTINCT。作用于所有列,不单是跟在其后的那一列。
限制结果(DBMS 实现不同)
1 | -- SQL Server |

第一个数字是检索的行数,第二个数字是指从哪开始。
如下:返回从第 5 行起的 5 行数据。只有 9 种产品,所以只返回了 4 行数据。
注:第一个被检索的行是第 0 行。
LIMIT 1 OFFSET 1会检索第 2 行。
1 | SELECT prod_name |

注释
1 | /* 多行注释 */ |
排序
按单/多列排序
该子句取一个或多个列名,以字母顺序排序数据。
1 | SELECT prod_name |
注: ORDER BY 子句的位置应该是 SELECT 语句中最后一条子句,否则会报错。

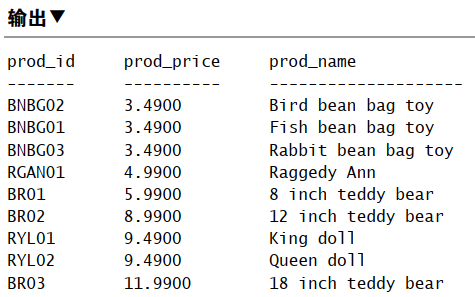
仅在多个行具有相同的 prod_price 值时,才对产品按 prod_name 进行排序。如果 prod_price 列中所有的值都是唯一的,则不会按 prod_name 排序。
按列位置排序
1 | SELECT prod_id, prod_price, prod_name -- 按列位置排序 |
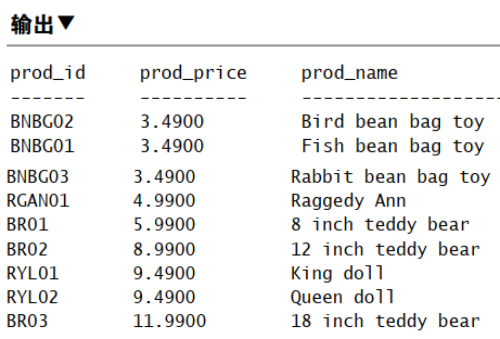
指定排序方向
1 | SELECT prod_id, prod_price, prod_name |
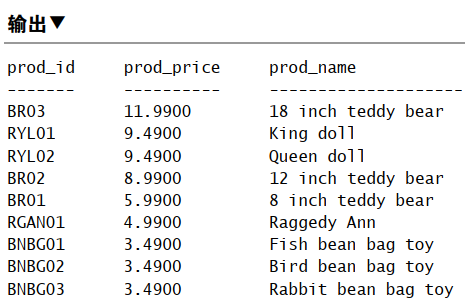
注:若想在多列上进行降序排序,必须对每一列指定 DESC。
DESCENDING 是全写,亦可使用。
ASCENDING「ASC」升序,默认无需指定。
区分大小写和排序顺序:
在字典(dictionary)排序顺序中,大小写相同,是多数 DBMS 默认做法,同时允许改变。
过滤数据
WHERE 子句
搜索条件(search criteria)也称过滤条件(filter condition)
1 | SELECT prod_name, prod_price |
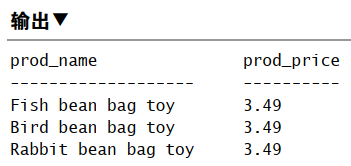
WHERE 操作符
操作符(operator)用来联结或改变 WHERE 子句中的子句的关键字,也称为逻辑操作符(logical operator)。
| 操 作 符 | 说 明 | 操 作 符 | 说 明 |
|---|---|---|---|
| = | 等于 | > | 大于 |
| <> | 不等于 | >= | 大于等于 |
| != | 不等于 | !> | 不大于 |
| < | 小于 | BETWEEN | 指定两个值之间(都包括) |
| <= | 小于等于 | IS NULL | 为 NULL 值 |
| !< | 不小于 |
1 | SELECT prod_name, prod_price |
NULL 无值(no value),与字段包含 0、空字符串或仅空格不同。
如上,返回空 prod_price 字段,不是价格为 0。
高级数据过滤
组合 WHERE 子句,AND OR IN NOT 操作符
1 | SELECT prod_id, prod_price, prod_name |
许多 DBMS 在 OR WHERE 子句的第一个条件满足时,就不再计算第二个条件了。
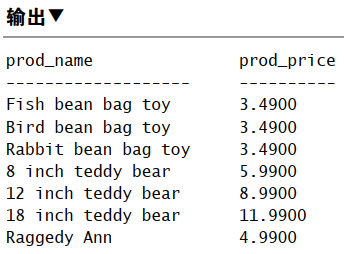
求值顺序,() 明确分组
1 | SELECT prod_name, prod_price |
检索由供应商 DLL01 和 BRS01 制造的所有产品,以上两种表达一样。
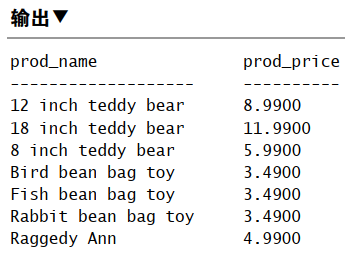
- IN 优点:
IN 操作符的语法更直观;
在与 AND 和 OR 组合使用 IN 时,求值顺序更容易管理;
IN 一般比一组 OR 执行更快;
IN 最大优点是可包含其他 SELECT 语句,能更动态地建立 WHERE 子句。
NOT 从不单独使用(总是与其他操作符一起使用),所以它的语法与其他操作符不同。
1 | SELECT prod_name |

MariaDB 支持使用 NOT 否定 IN、BETWEEN 和 EXISTS 子句。大多数
DBMS 允许使用 NOT 否定任何条件。
通配符过滤
通配符(wildcard)用来匹配值的一部分的特殊字符。
搜索模式(search pattern)由字面值、通配符或两者组合构成的搜索条件。
谓词(predicate)即操作符作为谓词时。从技术上说,LIKE 是谓词。虽然最终的结果是相同的。
通配符搜索只能用于文本字段(字符串)。
通配符 % _ []
% 表示任何字符出现任意次数(包括 0)。
子句 WHERE prod_name LIKE '%' 不会匹配产品名称为 NULL 的行。
_ 只匹配单个字符。(DB2 不支持通配符 _)
[] 用来指定一个字符集,必须匹配指定位置的一个字符。
(SQL Server 支持集合,MySQL,Oracle,DB2,SQLite 都不支持。)
此通配符可以用前缀字符 ^(脱字号)来否定。
1 | SELECT prod_id, prod_name |
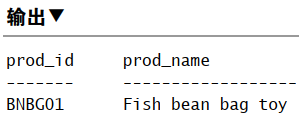
注:字符串后面可能用空格填充,故匹配以某字母结尾,需要后面加百分号
y%
1 | SELECT cust_contact |
通配符技巧
不要过度使用通配符。耗时长,优先使用其他能达到相同目的的操作符。
尽量不要把它们用在搜索模式的开始处,这样搜索起来是最慢的。
创建计算字段
计算字段
计算字段是运行时在 SELECT 语句内创建的。
字段(field)基本上与列的意思相同,经常互换使用,不过数据库列一般称为列,而字段这个术语通常在计算字段这种场合下使用。
拼接字段
拼接(concatenate)将值联结到一起(将一个值附加到另一个值)构成单个值。
SQL Server 使用 + 号。
DB2、Oracle、PostgreSQL 和 SQLite 使用 ||。
MySQL 和 MariaDB 使用特殊函数 Concat。
1 | SELECT vend_name + ' (' + vend_country + ')' |

许多数据库保存填充为列宽的文本值,不需要这些空格时如下:
1 | SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' |

别名 AS
别名(alias)有时也称导出列(derived column)
执行算术计算
1 | SELECT |
操作符:+ 加 - 减 * 乘 / 除
函数
| 函 数 | 语 法 |
|---|---|
| 提取字符串的组成部分 | DB2、Oracle、PostgreSQL 和 SQLite 使用 SUBSTR();MariaDB、MySQL 和 SQL Server 使用 SUBSTRING() |
| 数据类型转换 | Oracle 每种类型的转换有一个函数;DB2 和 PostgreSQL 使用 CAST();MariaDB、MySQL 和 SQL Server 使用 CONVERT() |
| 取当前日期 | DB2 和 PostgreSQL 使用 CURRENT_DATE;MariaDB 和 MySQL 使用 CURDATE();Oracle 使用 SYSDATE;SQL Server 使用 GETDATE();SQLite 使用 DATE() |
多数 SQL 支持以下类型函数:
- 处理文本字符串的文本函数;
- 数值数据上进行算术操作的数值函数;
- 处理日期时间并提取特定成分的日期和时间函数;
- 格式化函数,如货币符号和千分位表示金额;
- 返回 DBMS 正使用的特殊信息的系统函数。
文本处理函数
1 | SELECT vend_name, UPPER(vend_name) AS vend_name_upcase |

| 函 数 | 说 明 |
|---|---|
| LEFT()(或使用子字符串函数) | 返回字符串左边的字符 DB2, PostgreSQL, MySQL, SQL Server |
| RIGHT()(或使用子字符串函数) | 返回字符串右边的字符 |
| LENGTH() DATALENGTH() LEN() | 返回字符串的长度 |
| LOWER() | 将字符串转换为小写 |
| UPPER() | 将字符串转换为大写 |
| LTRIM() | 去掉字符串左边的空格 |
| RTRIM() | 去掉字符串右边的空格 |
| TRIM() | 去掉字符串两边的空格 |
| SUBSTR() SUBSTRING() | 提取字符串的组成部分 |
| SOUNDEX() | 返回字符串的 SOUNDEX值 |
SOUNDEX 是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。能对字符串进行发音比较而不是字母比较。虽然 SOUNDEX 不是 SQL 概念,但多数 DBMS 都提供支持。
PostgreSQL 不支持 SOUNDEX()。
如果在创建 SQLite 时使用了 SQLITE_SOUNDEX 编译时选项,那么 SOUNDEX() 才可用。因为 SQLITE_SOUNDEX 不是默认编译时选项,所以多数 SQLite 实现不支持 SOUNDEX()。
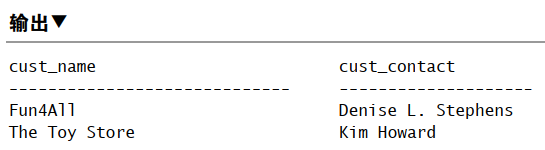
1 | SELECT cust_name, cust_contact |
表中的联系名是 Michelle Green 有误,正确拼写是 Michael Green。
日期和时间函数
1 | SELECT order_num |
数值函数
| 函 数 | 说 明 |
|---|---|
| ABS() | 返回一个数的绝对值 |
| SIN() | 返回一个角度的正弦 |
| COS() | 返回一个角度的余弦 |
| TAN() | 返回一个角度的正切 |
| EXP() | 返回一个数的指数值 |
| SQRT() | 返回一个数的平方根 |
| PI() | 返回圆周率 π 的值 |
汇总数据
聚集函数
聚集函数(aggregate function)对某些行运行的函数,计算并返回一个值。
| 函 数 | 说 明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
1 | SELECT AVG(prod_price) AS avg_price -- AVG() 只用于单列,忽略列值为 NULL 的行。 |
.png)
注:最好指定别名以包含某个聚集函数的结果。否则许多 SQL 可能会产生错误消息。
使用 COUNT(*) 对表中行的数目进行计数,包括空值(NULL)。
使用 COUNT(column) 对特定列中具有值的行进行计数,忽略 NULL 值。
1 | SELECT COUNT(cust_email) AS num_cust |
MAX() 一般用来找出最大的数值或日期值;用于文本数据时,返回按该列排序后的最后一行,忽略列值为 NULL 的行。MIN() 相反。
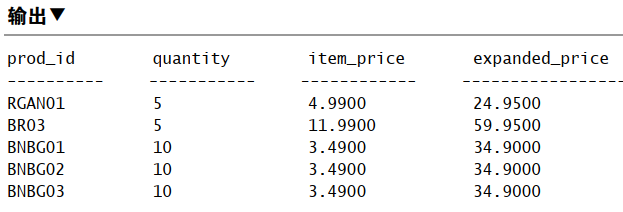
1 | SELECT SUM(item_price*quantity) AS total_price -- 计算总价钱 |
聚集不同值
对所有行执行计算,指定 ALL 参数(默认)或不指定参数。
只包含不同的值,指定 DISTINCT 参数。
1 | SELECT AVG(DISTINCT prod_price) AS avg_price -- 平均值只考虑各个不同的价格,相同价格会排除 |
DISTINCT 不能用于 COUNT(*),只能用于 COUNT()。
DISTINCT 必须使用列名,不能用于计算或表达式。
分组
创建分组 GROUP BY
1 | SELECT vend_id, COUNT(*) AS num_prods |

GROUP BY 子句可以包含任意数目的列,还可以嵌套,但不能是聚集函数。
如果在 SELECT 中使用表达式,则必须在 GROUP BY 中指定相同的表达式,不能使用别名。
多数 SQL 实现不允许 GROUP BY 列带有长度可变的数据类型(如文本或备注型字段)
除聚集计算语句外,SELECT 语句中的每一列都必须在 GROUP BY 中给出。
如果分组列中包含具有 NULL 值的行,则 NULL 将作为一个分组返回。列中多行 NULL 值,将分为一组。
SQL Server 等有些 SQL 实现在 GROUP BY 中支持可选的 ALL 子句。用来返回所有分组,即使是没有匹配行的分组也返回(在此情况下,聚集将返回 NULL)。
通过相对位置指定列:
有些 SQL 实现允许根据 SELECT 列表中的位置指定 GROUP BY 的列。
如GROUP BY 2, 1表示按选择的第二个列分组,再按第一个列分组。
过滤分组
WHERE 过滤行,HAVING 过滤分组。HAVING 支持所有 WHERE 操作符。
WHERE 在数据分组前进行过滤,HAVING 在分组后过滤。
WHERE 排除的行不包括在分组中,可能会改变计算值,从而影响 HAVING 中基于这些值过滤掉的分组。
使用 HAVING 时应该结合 GROUP BY,而 WHERE 用于标准的行级过滤。
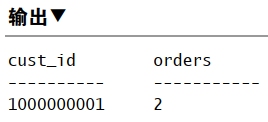
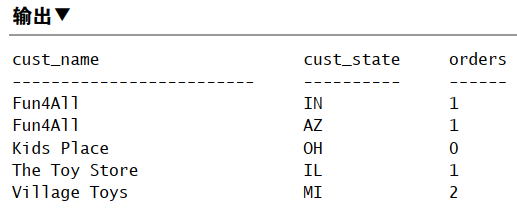
1 | SELECT cust_id, COUNT(*) AS orders |
排序和分组
| ORDER BY | GROUP BY |
|---|---|
| 对产生的输出排序 | 对行分组,输出可能不是分组的顺序 |
| 任意列都可用(甚至非选择的列) | 只能使用选择列或表达式列,且必须使用其表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
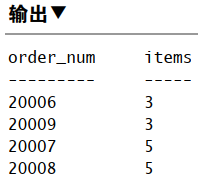
一般在使用 GROUP BY 时,也给出 ORDER BY。这是保证数据正确排序的唯一方法。
1 | SELECT order_num, COUNT(*) AS items |
SELECT 子句顺序
| 子 句 | 说 明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
子查询
子查询过滤
1 | SELECT cust_name, cust_contact |
子查询的 SELECT 语句只能查询单个列。
作为计算字段使用
1 | SELECT |
子查询对检索出的每个顾客执行一次。
联结表
联结(join)是一种机制,用来在一条 SELECT 语句中关联表。要保证所有联结都有 WHERE 子句。
关系表的设计就是要把信息分解成多个表,一类数据一个表。各表通过某些共同的值互相关联(所以才叫关系数据库)。
可伸缩(scale)能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称为可伸缩性好(scale well)。
创建联结
1 | SELECT vend_name, prod_name, prod_price |

笛卡儿积(cartesian product)由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。返回笛卡儿积的联结,也称叉联结(cross join)
1 | SELECT vend_name, prod_name, prod_price |
内联结
以上联结称为等值联结(equijoin),基于两个表之间的相等测试。也称为内联结(inner join)
1 | SELECT vend_name, prod_name, prod_price |
两个表之间的关系是以 INNER JOIN 指定的部分 FROM 子句。联结条件用特定的 ON 子句而不是 WHERE 子句给出。传递给 ON 的实际条件与传递给 WHERE 的相同。
ANSI SQL 规范首选 INNER JOIN 语法。
联结多个表
1 | SELECT prod_name, vend_name, prod_price, quantity |
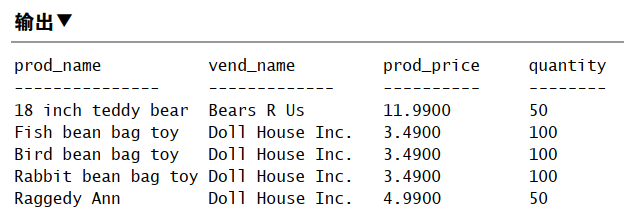
这个例子显示订单 20007 中的物品。订单物品存储在 OrderItems 表中。
每个产品按其产品 ID 存储,它引用 Products 表中的产品。这些产品通
过供应商 ID 联结到 Vendors 表中相应的供应商,供应商 ID 存储在每个
产品的记录中。
DBMS 对联结中表的最大数目有限制。
1 | SELECT cust_name, cust_contact |
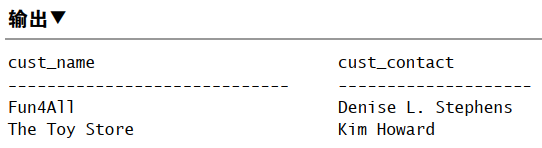
表别名
表别名只在查询执行中使用。
1 | SELECT cust_name, cust_contact |
Oracle 不支持 AS 关键字,直接指定即可
Customers C
自联结
self-join
1 | SELECT cust_id, cust_name, cust_contact |
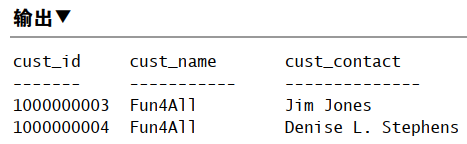
- 用自联结而不用子查询
自联结通常作为外部语句,用来替代从相同表中检索数据使用的子查询语句。许多 DBMS 处理联结远比子查询快。
自然联结
标准联结(内联结)返回所有数据,相同的列甚至多次出现。
自然联结排除多次出现,使每一列只返回一次。
自然联结(natural join)只能选择唯一的列,一般通过对一个表使用通配符(SELECT *),而对其他表的列使用明确的子集来完成。
1 | SELECT |
很可能永远都不会用到不是自然联结的内联结。
外联结
外联结(outer join)包含了那些在相关表中没有关联行的行。
1 | SELECT Customers.cust_id, Orders.order_num |
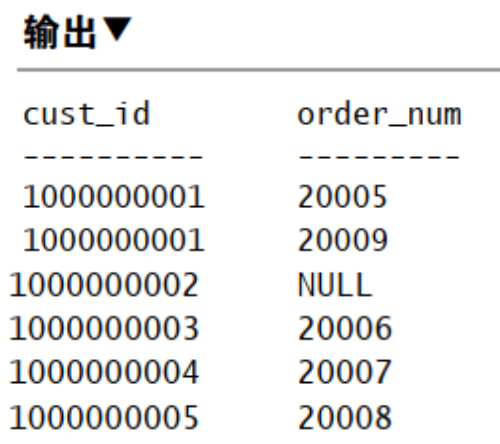
使用 OUTER JOIN 时,必须使用 RIGHT 或 LEFT 关键字指定包括其所有行的表。RIGHT 指出的是 OUTER JOIN 右边的表,LEFT 指左边。
SQLite 支持 LEFT OUTER JOIN,但不支持 RIGHT OUTER JOIN。
全外联结(full outer join)检索两个表中的所有行并关联那些可以关联的行。
1 | SELECT Customers.cust_id, Orders.order_num |
MariaDB、MySQL 和 SQLite 不支持全外联结。
带聚集函数的联结
1 | SELECT Customers.cust_id, |
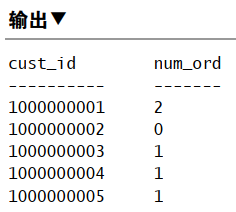
一般使用内联结,但使用外联结也有效。
总是提供联结条件,否则会得出笛卡儿积。
组合查询
组合查询通常称为并(union)或复合查询(compound query)
使用情况:
在一个查询中从不同的表返回结构数据;
对一个表执行多个查询,按一个查询返回数据。
1 | SELECT cust_name, cust_contact, cust_email |
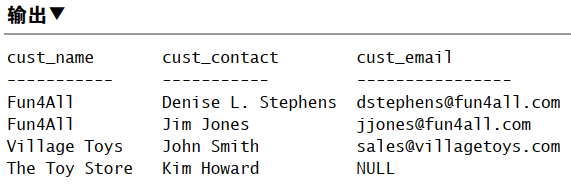
UNION 规则
UNION 必须由两条或以上的 SELECT 语句组成,语句之间用 UNION 分隔;
UNION 中每个查询必须包含相同的列、表达式或聚集函数;
列数据类型必须兼容:类型不必完全相同,但必须是 DBMS 可以隐含转换的类型(如,不同数值类型或不同日期类型)。
注:结合 UNION 使用的 SELECT 语句遇到不同的列名,会返回第一个名字,其他语句使用时也必须以第一个为准,否则报错。
包含或取消重复的行 UNION ALL
1 | SELECT cust_name, cust_contact, cust_email |
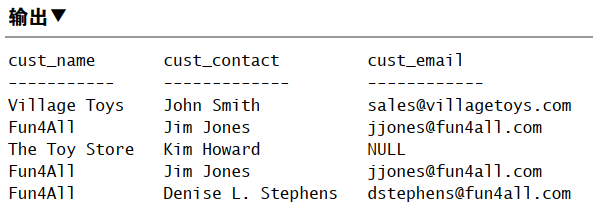
对组合查询结果排序
使用 UNION 时,只能使用一条 ORDER BY,必须位于最后一条 SELECT 语句之后。
1 | SELECT cust_name, cust_contact, cust_email |
某些 DBMS 还支持其他 UNION:
EXCEPT(有时称为MINUS)用来检索只在第一个表中存在而在第二个表中不存在的行;而INTERSECT用来检索两个表中都存在的行。实际上这两种很少使用,因为相同结果可用联结得到。
插入数据 INSERT
插入完整行
必须给每一列提供一个值,没有值则指定 NULL。
1 | -- 不安全,避免使用,顺序要和表一致。 |
1 | -- 更安全,次序随意,以列名匹配。 |
不能插入同一条记录两次,主键(cust_id)的值必须有唯一性。
插入部分行
1 | INSERT INTO Customers(cust_id, |
- 省略列
该列定义为允许 NULL 值(无值或空值);
在表定义中给出默认值。
插入检索出的数据
从 CustNew 表中读出数据并插入到 Customers 表。
1 | INSERT INTO Customers(cust_id, |
注:INSERT SELECT 中的列名,这里不一定要求列名匹配,以两个表对应的列位置匹配。
INSERT 通常只插入一行。要插入多行,必须执行多个 INSERT 语句。INSERT SELECT 是例外。
一个表复制到另一个表
CREATE SELECT 语句(SQL Server 也可用 SELECT INTO)(DB2 不支持 CREATE SELECT)。
1 | -- MySQL, MariaDB, Oracle, PostgreSQL, SQLite, SQL Server |
SELECT INTO 是试验新 SQL 语句前进行表复制的很好工具,不影响实际数据。
SELECT INTO 注意事项
任何 SELECT 选项和子句都可使用;
可利用联结从多个表插入数据;
不管从多少表中检索数据,数据只能插入到一个表中。
更新数据
不要省略 WHERE 子句。UPDATE 语句以 WHERE 结束,它告诉 DBMS 更新哪一行。
1 | UPDATE Customers -- 要更新的表 |
删除数据
1 | DELETE FROM Customers |
使用外键确保引用完整性的一个好处是 DBMS 通常可以防止删除某数据与其他表相关联的行。
如,要从 Products 表中删除一个产品,而这个产品用在 OrderItems 的已有订单中,那么 DELETE 语句将抛出错误并中止。这是总要定义外键的另一个理由。
DELETE 删除整行而不是列。删除指定列,用 UPDATE 语句。
想从表中删除所有行,可使用 TRUNCATE TABLE 语句速度更快(因为不记录数据的变动)。
更新和删除指导原则
除非打算更新和删除每一行,否则绝对带着 WHERE 子句。
在 UPDATE 或 DELETE 语句使用 WHERE 子句前,应先用 SELECT 进行测试,保证它过滤的是正确的记录,以防编写的 WHERE 子句不正确。
1 | SELECT * FROM Customers |
表
创建表 CREATE TABLE
1 | CREATE TABLE Products( -- 新表名 |
允许 NULL 值的列也允许在插入行时不给出该列的值。
不允许的列不接受没有列值的行,即插入或更新行时,该列必须有值。
只有不允许 NULL 值的列可作为主键。
NULL 值不是空字符串,如果指定 ''(其间无字符),这在 NOT NULL 列中是允许的。空字符串是一个有效的值,它不是无值。
指定默认值 DEFAULT
1 | CREATE TABLE OrderItems( |
- 获得系统日期
| DBMS | 函数/变量 |
|---|---|
| DB2 | CURRENT_DATE |
| MySQL | CURRENT_DATE() |
| Oracle | SYSDATE |
| PostgreSQL | CURRENT_DATE |
| SQL Server | GETDATE() |
| SQLite | date(‘now’) |
更新表 ALTER TABLE
许多 DBMS 不允许删除或更改表中的列,允许重命名;
限制对已经填有数据的列进行更改,对未填有数据的列几乎无限制。
1 | ALTER TABLE Vendors |
SQLite 不支持用 ALTER TABLE 定义主键和外键,必须在最初创建表时指定。
复杂的表结构更改一般需要手动删除:
- 创建一个新表;
- 用 INSERT SELECT 语句从旧表复制数据到新表,按需要修改;
- 检验包含所需数据的新表;
- 重命名旧表(若确定,可删除它);
- 用旧表名字重命名新表;
- 重新创建触发器、存储过程、索引和外键。
删除表 DROP TABLE
删除表没有确认步骤,不能撤销,将永久删除。
1 | DROP TABLE CustCopy; |
重命名表
DB2、MariaDB、MySQL、Oracle、PostgreSQL 使用 RENAME 语句;
SQL Server 使用 sp_rename 存储过程;
SQLite 使用 ALTER TABLE 语句。
视图
视图是虚拟的表。表包含数据,视图只包含使用时动态检索数据的查询。
SQLite 仅支持只读视图,所以视图可以创建、读,但内容不能更改。
所有 DBMS 一致支持视图创建语法。
删除视图,DROP VIEW viewname;
覆盖或更新视图,必须先删除再重新创建。
1 | SELECT cust_name, cust_contact |
视图应用
重用 SQL 语句。
简化复杂的 SQL 操作。
使用表的一部分而不是整个表。
保护数据。可以授予用户访问表的特定部分的权限,而不是整个表的访问权限。
更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
视图规则和限制
视图必须唯一命名,不能和其他表名重复。
创建的视图数目没有限制,必须具有足够的访问权限。
视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造视图。所允许的嵌套层数在不同的 DBMS 中有所不同(嵌套视图可能会严重降低查询性能,因此使用前应进行全面测试)。
许多 DBMS 禁止在视图查询中使用 ORDER BY 子句。
有些 DBMS 要求对返回的所有列进行命名,如果列是计算字段,则需要使用别名。
视图不能索引,也不能有关联的触发器或默认值。
有些 DBMS 把视图作为只读的查询,这表示可以从视图检索数据,但不能将数据写回底层表。
有些 DBMS 允许创建这样的视图,它不能进行导致行不再属于视图的插入或更新。例如有一个视图,只检索带有邮件地址的顾客。如果更新某个顾客,删除他的电子邮件地址,将使该顾客不再属于视图。这是允许的默认行为,但有的 DBMS 可能会阻止。
用视图简化复杂的联结
1 | CREATE VIEW ProductCustomers AS |
1 | SELECT cust_name, cust_contact |
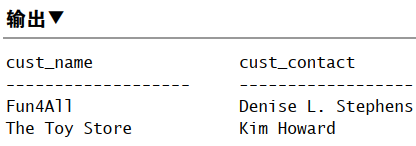
用视图重新格式化检索出的数据
1 | SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' |

1 | -- 视图格式化 |
用视图过滤不想要的数据
1 | CREATE VIEW CustomerEMailList AS |
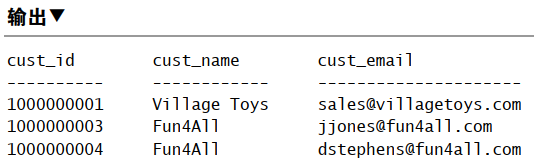
使用视图与计算字段
1 | CREATE VIEW OrderItemsExpanded AS |
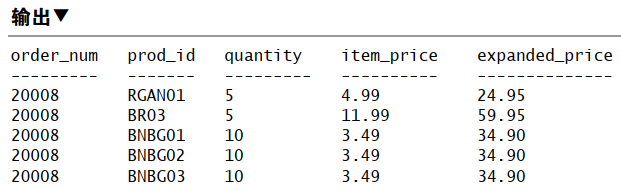
存储过程
存储过程就是为以后使用而保存的一条或多条 SQL 语句。可将其视为批文件。通常以编译过的形式存储,所以 DBMS 处理命令所需的工作量少,提高了性能。
SQLite 不支持存储过程。
执行存储过程
EXECUTE 接受存储过程名和需要传递给它的任何参数。
1 | EXECUTE AddNewProduct('JTS01', -- 供应商 ID(Vendors 表的主键) |
这 4 个参数匹配存储过程中 4 个预期变量(定义为存储过程自身的组成部分)。此存储过程将新行添加到 Products 表,并将传入的属性赋给相应的列。
另一个需要值的 prod_id 列是这个表的主键,最好是使生成此 ID 的过程自动化(而不是依赖于最终用户的输入)。
存储过程所完成的工作:
验证传递的数据,保证所有参数都有值;
生成用作主键的唯一 ID;
将新产品插入表,在合适的列中存储生成的主键和传递的数据。具体可选项:
参数可选,具有不提供参数时的默认值。
不按次序给出参数,以「参数=值」方式给出参数值。
输出参数,允许存储过程在正执行的应用程序中更新所用的参数。
用 SELECT 语句检索数据。
返回代码,允许存储过程返回一个值到正在执行的应用程序。
创建存储过程
1 | -- Oracle 版本,对邮件发送清单中具有邮件地址的顾客进行计数。 |
1 | -- 调用 Oracle 版本 |
1 | -- SQL Server |
SQL Server 中称这些自动增量的列为标识字段(identity field)
其他 DBMS 称之为自动编号(auto number)或序列(sequence)
DBMS 对日期使用默认值(GETDATE() 函数),订单号自动生成。
在 SQL Server 上可在全局变量 @@IDENTITY 中得到,它返回到调用程序(这里的 SELECT)。
事务处理
使用事务处理(transaction processing),通过确保成批的 SQL 操作完全执行或完全不执行,来维护数据库完整性。
事务(transaction)一组 SQL 语句;
回退(rollback)撤销指定 SQL 语句的过程;
提交(commit)将未存储的 SQL 语句结果写入数据库表;
保留点(savepoint)事务处理中设置的临时占位符(placeholder),可以对它发布回退(与回退整个事务处理不同)。
事务处理用来管理 INSERT、UPDATE 和 DELETE 语句。不能回退 SELECT 语句,也没必要,也不能回退 CREATE 或 DROP 操作。进行回退时,这些操作也不撤销。
控制事务处理
1 | -- SQL Server |
ROLLBACK
1 | DELETE FROM Orders; |
COMMIT
一般 SQL 语句都是针对数据库表直接执行和编写的,即隐式提交(implicit commit),提交(写或保存)操作是自动进行的。
在事务处理块中,提交不会隐式进行。有的 DBMS 按隐式提交处理事务端。
1 | -- SQL Server |
保留点
每个保留点都要取能够标识它的唯一名字。保留点越多越好。
1 | -- MariaDB、MySQL 和 Oracle |
游标
游标(cursor)是一个存储在 DBMS 服务器上的数据库查询,它不是一条 SELECT 语句,而是被该语句检索出来的结果集。在存储了游标之后,应用程序可以根据需要滚动或浏览其中的数据。
SQLite 支持的游标称为步骤(step)
常见特性
能标记游标为只读;
能控制可以执行的定向操作(向前、向后、第一、最后、绝对位置和相对位置等);
能标记某些列为可编辑的,某些不可编辑;
规定范围,使游标对创建它的特定请求(如存储过程)或对所有请求可访问;
指示 DBMS 对检索出的数据进行复制,使数据在游标打开和访问期间不变化。
使用游标
使用游标前,必须声明。这个过程实际上没有检索数据,只是定义要使用的 SELECT 语句和游标选项;
一旦声明,就必须打开游标以供使用。这个过程用前面定义的 SELECT 语句把数据实际检索出来;
对于填有数据的游标,根据需要检索各行;
结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具体 DBMS)。
创建游标 DECLARE
1 | -- DB2、MariaDB、MySQL 和 SQL Server |
使用游标 OPEN CURSOR
1 | OPEN CURSOR CustCursor |
FETCH 指出要检索哪些行,从何处检索它们以及将它们放于何处(如变量名)。
1 | -- Oracle |
关闭游标 CLOSE
1 | -- DB2、 Oracle 和 PostgreSQL |
高级 SQL 特性
约束
约束(constraint)管理如何插入或处理数据库数据的规则。
大多数约束是在表定义中定义的。
主键
主键是一种特殊的约束,用来保证一列(或一组列)中的值是唯一的,而且永不改动。
表中任意列只要满足以下条件,都可用于主键:
任意两行的主键值都不相同;
每行都具有一个主键值(即列中不允许 NULL 值);
包含主键值的列从不修改或更新(大多数 DBMS 不允许这么做);
主键值不能重用,如果从表中删除某一行,其主键值不分配给新行。
1 | CREATE TABLE Vendors( |
SQLite 不允许使用 ALTER TABLE 定义键,要求在初始的 CREATE TABLE 语句中定义它们。
外键
外键是表中的一列,其值必须列在另一表的主键中。
REFERENCES 关键字,表示 cust_id 中的任何值都必须是 Customers 表的 cust_id 中的值。
1 | CREATE TABLE Orders( |
有的 DBMS 支持级联删除(cascading delete)特性。如果启用,该特性在从一个表中删除行时删除所有相关的数据。如,从 Customers 表中删除某个顾客,则任何关联的订单行也会被自动删除。
唯一约束
唯一约束用来保证一列(或一组列)中的数据是唯一的。类似于主键,但存在以下重要区别:
- 表可包含多个唯一约束,但每个表只允许一个主键。
- 唯一约束列可包含 NULL 值。
- 唯一约束列可修改或更新。
- 唯一约束列的值可重复使用。
- 与主键不一样,唯一约束不能用来定义外键。
唯一约束既可以用 UNIQUE 关键字在表定义中定义,也可以用单独的 CONSTRAINT 定义。
检查约束
检查约束用来保证一列(或一组列)中的数据满足一组指定的条件。
常见用途:
- 检查最小或最大值。如,防止 0 个物品的订单。
- 指定范围。
- 只允许特定的值。
1 | CREATE TABLE OrderItems( |
索引
索引用来排序数据以加快搜索和排序操作的速度。
开始创建索引前:
- 索引改善检索操作的性能,但降低了数据插入、修改和删除的性能。在执行这些操作时,DBMS 必须动态地更新索引。
- 索引数据可能要占用大量的存储空间。
- 并非所有数据都适合做索引。
- 索引用于数据过滤和排序。
- 可在索引中定义多个列(如州加上城市)。这样的索引仅在以州加城市的顺序排序时有用。
1 | -- 不同 DBMS 创建索引的语句变化很大 |
触发器
触发器是特殊的存储过程,它在特定的数据库活动发生时自动执行。
触发器可与特定表上的 INSERT、UPDATE 和 DELETE 操作相关联。
与存储过程不一样,触发器与单个的表相关联。与 Orders 表上的 INSERT 操作相关联的触发器只在 Orders 表中插入行时执行。
触发器内的代码具有以下数据的访问权:
- INSERT 操作中的所有新数据;
- UPDATE 操作中的所有新旧数据;
- DELETE 操作中删除的数据。
常见用途:
- 保证数据一致。如,在 INSERT 操作中将所有州名转换为大写。
- 基于某个表的变动在其他表上执行活动。如,每当更新或删除一行时将审计跟踪记录写入某个日志表。
- 进行额外的验证并根据需要回退数据。如,保证某个顾客的可用资金不超限定,如果已经超出,则阻塞插入。
- 计算计算列的值或更新时间戳。
1 | -- SQL Server |
一般来说,约束处理比触发器快,因此应该尽量使用约束。
数据库安全
一般说来,需要保护的操作:
- 对数据库管理功能(创建表、更改或删除已存在的表等)的访问;
- 对特定数据库或表的访问;
- 访问的类型(只读、对特定列的访问等);
- 仅通过视图或存储过程对表进行访问;
- 创建多层次的安全措施,从而允许多种基于登录的访问和控制;
- 限制管理用户账号的能力。
安全性使用 SQL 的 GRANT 和 REVOKE 语句来管理,不过大多数 DBMS 提供了交互式的管理实用程序,在内部使用 GRANT 和 REVOKE。
样例表脚本
Vendors 表
| 列 | 说 明 |
|---|---|
| vend_id(主键) | 唯一的供应商 ID |
| vend_name | 供应商名 |
| vend_address | 供应商的地址 |
| vend_city | 供应商所在城市 |
| vend_state | 供应商所在州 |
| vend_zip | 供应商地址邮政编码 |
| vend_country | 供应商所在国家 |
Products 表
| 列 | 说 明 |
|---|---|
| prod_id(主键) | 唯一的产品ID |
| vend_id | 产品供应商ID(关联到Vendors表的vend_id) |
| prod_name | 产品名 |
| prod_price | 产品价格 |
| prod_desc | 产品描述 |
为实施引用完整性,在 vend_id 上定义一个外键,关联到 Vendors 的 vend_id 列。
Customers 表
| 列 | 说 明 |
|---|---|
| cust_id(主键) | 唯一的顾客ID |
| cust_name | 顾客名 |
| cust_address | 顾客的地址 |
| cust_city | 顾客所在城市 |
| cust_state | 顾客所在州 |
| cust_zip | 顾客地址邮政编码 |
| cust_country | 顾客所在国家 |
| cust_contact | 顾客的联系名 |
| cust_email | 顾客的电子邮件地址 |
Orders 表
| 列 | 说 明 |
|---|---|
| order_num | 唯一的订单号 |
| order_date | 订单日期 |
| cust_id | 订单顾客 ID(关联到 Customers 表的 cust_id) |
OrderItems 表
| 列 | 说 明 |
|---|---|
| order_num(主键) | 订单号(关联到 Orders 表的 order_num) |
| order_item(主键) | 订单物品号(订单内的顺序) |
| prod_id | 产品 ID(关联到 Products 表的prod_id) |
| quantity | 物品数量 |
| item_price | 物品价格 |
create.txt 包含创建 5 个数据库表(包括定义所有主键和外键约束)的 SQL 语句。
populate.txt 包含用来填充这些表的 SQL INSERT 语句。
1 | -- Example table creation scripts for MySQL & MariaDB |
SQL 语句语法
约定
| 符号指出多选择之一;[] 包含关键字或子句是可选的。
COMMIT
将事务写入数据库。
1 | COMMIT [TRANSACTION] |
CREATE INDEX
再一个或多个列上创建索引。
1 | CREATE INDEX indexname |
CREATE PROCEDURE
创建存储过程。Oracle 语法不同。
1 | CREATE PROCEDURE procedurename [parameters] [options] |
CREATE TABLE
1 | CREATE TABLE tablename( |
ALTER TABLE
更新已存在表结构。
1 | ALTER TABLE tablename( |
CREATE VIEW
创建一个或多个表上的视图。
1 | CREATE VIEW viewname AS |
DELETE
从表中删除一行或多行。
1 | DELETE FROM tablename |
DROP
永久删除数据库对象。
1 | DROP INDEX|PROCEDURE|TABLE|VIEW indexname|procedurename|tablename|viewname; |
INSERT
为表添加一行。
1 | INSERT INTO tablename[(columns, ...)] |
INSERT SELECT
将 SELECT 的结果插入到一个表。
1 | INSERT INTO tablename[(columns, ...)] |
ROLLBACK
撤销一个事务块。
1 | ROLLBACK [TO savepointname]; |
SELECT
从一个或多个表(视图)中检索数据。
1 | SELECT columnname, ... |
UPDATE
更新表中的一行或多行。
1 | UPDATE tablename |
SQL 数据类型
字符串(单引号内)
| 数据类型 | 说 明 |
|---|---|
| CHAR | 1~ 255 个字符的定长字符串。它的长度必须在创建时规定 |
| NCHAR | CHAR的特殊形式,用来支持多字节或 Unicode 字符(此类型的不同实现变化很大) |
| NVARCHAR | TEXT 的特殊形式,用来支持多字节或 Unicode 字符 |
| TEXT(也称 LONG、MEMO 或 VARCHAR) | 变长文本 |
定长字符串的长度在创建表时指定,空余字符用空格填充,或根据需要补为 NULL。
数值(不用引号)
| 数据类型 | 说 明 |
|---|---|
| BIT | 单个二进制位值,主要用于开/关标志 |
| DECIMAL(或 NUMERIC) | 定点或精度可变的浮点值 |
| FLOAT(或 NUMBER) | 浮点值 |
| REAL | 4 字节浮点值 |
| INT(或 INTEGER) | 4 字节整数值,支持 −2147483648~2147483647 |
| SMALLINT | 2 字节整数值,支持−32768~32767 |
| TINYINT | 1 字节整数值,支持0~255 |
货币数据类型
MONEY 或 CURRENCY,有特定取值范围的 DECIMAL 数据类型。
日期和时间
| 数据类型 | 说 明 |
|---|---|
| DATE | 日期值 |
| DATETIME(或 TIMESTAMP) | 日期时间值 |
| SMALLDATETIME | 日期时间值,精确到分(无秒) |
| TIME | 时间值 |
ODBC 日期
该格式对每种数据库都起作用。
日期 {d '2020-12-30'}
时间 {t '12:30:59'}
日期时间 {ts '2020-12-30 12:30:59'}
二进制
兼容性最差,最少使用,可包含任何数据。
| 数据类型 | 说 明 |
|---|---|
| BINARY | 定长二进制数据(最大长度从 255B 到 8000B,依赖于具体的实现) |
| RAW(某些实现为 BINARY) | 定长二进制数据,最多 255B |
| VARBINARY | 变长二进制数据(最大长度一般在 255B 到8000B 间变化,依赖于具体的实现) |
| LONG RAW | 变长二进制数据,最长 2GB |
SQL 关键字
保留字
1 | ABORT |
Refer
《SQL必知必会(第5版)》
《MySQL必知必会(第1版)》
PS
数据库语言除了关键字一般全大写有点看不习惯,整体语句比较简单,但逻辑较冗杂,刷力扣的时候感觉代码格式上也没有统一的标准,故行文中排版稍有混乱,日后再研究这些细节。